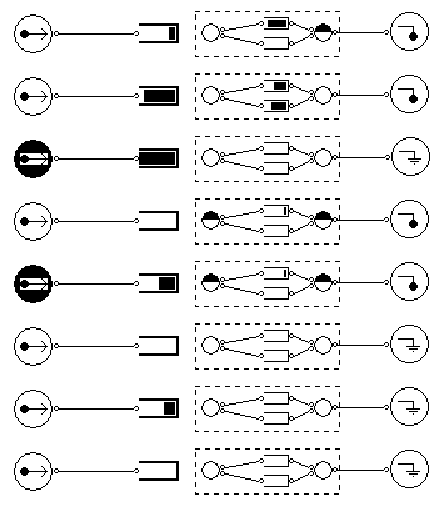
Figure 1: The HASE model of the VLXbar network.
Figure 1 below shows the simulation model constructed using HASE. Down the left hand side are eight sources; these feed packets into the input queues. The outputs are also buffered; each output is shown in a dotted box and includes two output queues and arbiters to decide (a) when a flit (each packet transmission is composed of a number of flits) can go into an output queue and (b) which one. The output sinks are at the right hand side of the picture. The crossbar interconnect is an NxN connection between the input queues and the output queues (not shown in this visualisation).
Figure 1: The HASE model of the VLXbar network.
During model animation the queues fill and empty, the arbiters show which way they are arbiting and the input and output sinks and sources show when they are blocked and busy.
The report VLXbar terminology and arbitration details the low level timing details, terminology and arbitration policy used in the VLXbar models.
For this model a hot spot probability parameter was used to decide to send a packet to a fixed destination rather than to a random one.
From a single run of the simulation, the output id a detailed timing diagram and statistics collected by each entity. As an example, the sink entity gives the number of packets and flits received at each output, and the minimum, average and maximum delays packets suffered, as shown in the following table.
(90% util, pkt size = 8, 10% hotspotting, 8 inputs, 1000 clk cycles):- u:sinks0 at 1000.050000: C Pkts:68, flits:545, delay:(9,24,47) u:sinks1 at 1000.050000: C Pkts:114, flits:915, delay:(15,127,221) u:sinks2 at 1000.050000: C Pkts:30, flits:241, delay:(15,19,35) u:sinks3 at 1000.050000: C Pkts:40, flits:326, delay:(15,21,36) u:sinks4 at 1000.050000: C Pkts:76, flits:608, delay:(15,51,130) u:sinks5 at 1000.050000: C Pkts:51, flits:408, delay:(15,20,45) u:sinks6 at 1000.050000: C Pkts:103, flits:824, delay:(9,119,240) u:sinks7 at 1000.050000: C Pkts:115, flits:926, delay:(9,74,157)For multiple runs of the simulation, the effect on output performance varying input parameters was obtained. The following graphs show the effects on the system components of varying the utilisation.
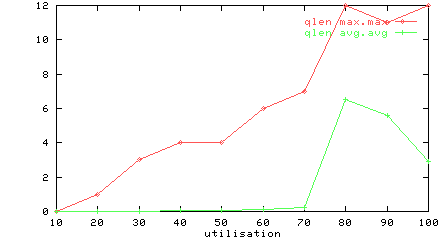
Figure 2: Utilisation vs Max input queue length.
Figure 2 shows how the maximum input queue length increases fairly linearly as utilisation increases.
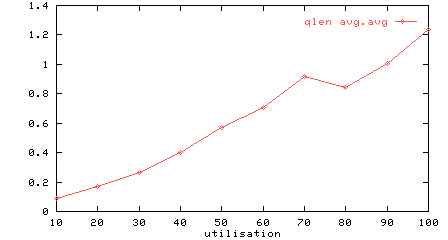
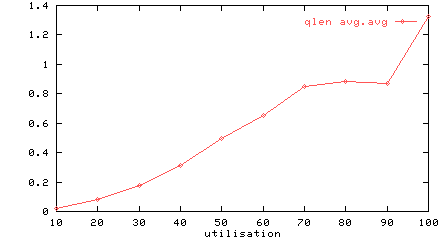
Figure 3: Utilisation vs output queues length
Figure 3 shows how the average output queue lengths increase up to an average of 1 at 70% utilisation and then level out. This is because once the output queue length hits an average of one, the outputs are saturated.
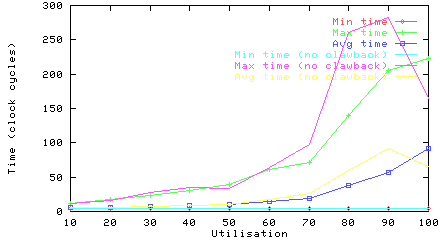
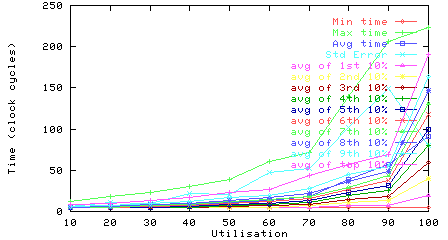
Figure 4: Utilisation vs packet delay distribution (with and without clawback)
The upper graph in Figure 4 shows how the average and maximum packet delay varies with utilisation. The lower graph shows the 10 percentile distribution. There is a the big jump at 80% in the maximum packet delay (and the slower growth in the average packet delay); some of the packets start to be very slow above 80% utilisation.
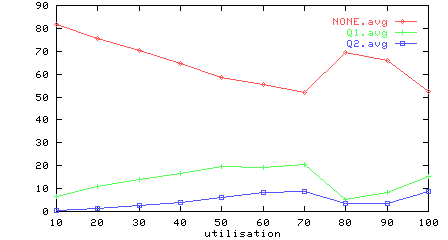
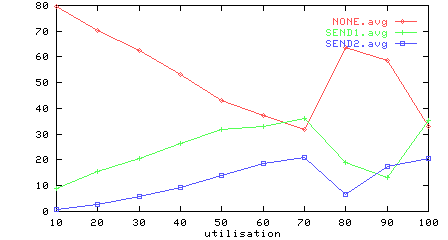
Figure 5: Utilisation vs output arbitration and multiplexor performance
Figure 5 shows the percentages of time the output arbiters and multiplexors are in the states NONE (i.e. idle), Q1 (arbitrating for output queue 1), Q2 (arbitrating for output queue 2) and SEND1 (i.e. sending from output queue 1 to the sink), SEND2 (i.e. sending from output queue 2 to the sink).
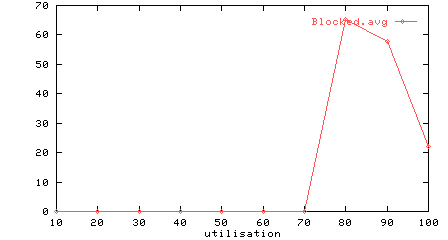
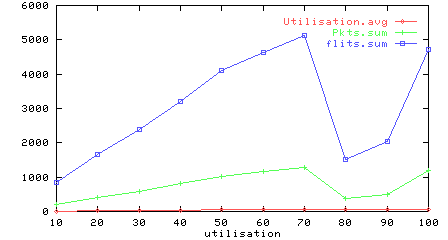
Figure 6: Utilisation vs source and sink performance
Figure 6 shows the influence of the network on the source (upper graph) and sink (lower graph); the source is never blocked until 80% utilisation, and the sink processes progressively more flits until the network starts to saturate.
void mstage_src::construct_route(int dest, int *buf, int *i)
{
/* Construct route from here to there */
*i = 0;
/* For each stage */
/* dest = bit pattern */
/* 00 11 01 10 */
/* Shift dest by log2(swsize)
* and with mask of swsize -1
*/
int mask = swsize-1;
int lgswsize = ilog2(swsize);
for (int s=nstages-1; s>=0; s--) {
buf[s] = dest & mask;
dest >>= lgswsize;
}
(*i) = nstages;
}
The basic idea is that the first flit arriving at the crossbar
determines the destination address which is stripped from the packet
when it leaves. In a multistage network with three stages, the first
flit of the packet determines the route through the first stage, the
next determins the route through the second and the third flit is the
address through the third crossbar. When the packet emerges, it has
lost its address flits and just contains data.
This is not a trivial task. The MPI interface has a large number of functions ranging from basic message passing to collective reductions, gathering and scattering of complex data sets, and a wide variety of synchronisation options.
MPI source code for an implementation on LANs was available, however, and this was used as the base for the simulation interface.
The layers from the MPI program down to the low level network simulation model are as follows:-
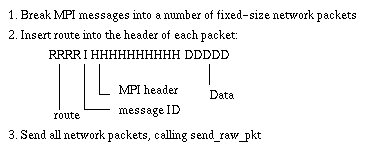
1. Break MPI messages into a number of fixed size network packets. 2. Insert route in the header of each network packet.3. Send all network packets, calling send_raw_pkt
Detailed hardware information was provided by Cray staff working at EPCC.
| Type | Size | Contents |
|---|---|---|
| 0 - | 3 | route,dest,cmd |
| 1 - | 6 | route,dest,cmd,ad1,ad2,src |
| 2 - | 8 | route,dest,cmd,ad1,ad2,src,rad1,rad2 |
| 3 - | -8 | route,dest,cmd,d1,d2,d3,d4,E5 |
| 4 - | 11 | route,dest,cmd,ad1,ad2,src,d1,d2,d3,d4 |
| 5 - | 23 | route,dest,cmd,d1..16 |
| 6 - | 26 | route,dest,cmd,ad1,ad2,src,d1..16 |
The transactions use the above packet types for requests and responses as follows:-
| Transaction | Request | Response |
|---|---|---|
| PE noncache rd | 1 | 3 |
| PE wr 1word | 4 | 0 |
| PE cache rd | 1 | 5 |
| PE wr 4word | 6 | 0 |
| BLT rd 1word | 2 | 4 |
| BLT wr 1word | 4 | 0 |
| BLT blk rd | 2 | 6 |
| BLT blk wr | 6 | 0 |
| pfetch rd | 1 | 3 |
| f&inc rd | 1 | 3 |
| f&inc wr | 4 | 0 |
| swap | 4 | 3 |
PE is the processing element, the BLT is a DMA device which has access to the network, pfetch stands for prefetch, f&inc and swap are used for synchronisation.
The 'node' of the torus contains two CPUs, a network interface and a router with 6 bidirectional connections (left, right, up, down, in, out) as well as connections to and from the network interface. The router is actually made up of three switches: the X switch, the Y switch and the Z switch. Each switch routes both ways in its own dimension, and also has input and output connections for messages which are turning a corner.
The HASE++ simulation code for building a node is:-
proc *pe0 = new proc(pe0name, new sim_port(nifname),
x,y,z,0,SRC_OK);
proc *pe1 = new proc(pe1name, new sim_port(nifname),
x,y,z,1,SRC_OK);
nif *n = new nif(nifname,
new sim_port(pe0name), new sim_port(pe1name),
new sim_port(btename), new sim_port(netoname),
new sim_port(netiname),x,y,z);
router *r = new router(new sim_port(nifname), new sim_port(nifname),
xp_i, xm_i,
yp_i, ym_i,
zp_i, zm_i,
x,y,z);
The router is made up of three switches:-
cswitch *xsw = new cswitch(xname,pein_i,xp_i,xm_i,
new sim_port(yname),
x,y,z,0);
cswitch *ysw = new cswitch(yname,new sim_port(xname),yp_i,ym_i,
new sim_port(zname),
x,y,z,1);
cswitch *zsw = new cswitch(zname,new sim_port(yname),zp_i,zm_i,
peout_i,
x,y,z,2);
This was implemented in the model of the switch using an array of buffers:-
// Virtual channels - each is an array of 8 flits. vc *vchan[3][4];
Arbitration must be done for the virtual channels as well as the physical connections. To give an idea of the complexity of the switch, the class definition file is given here:-
class cswitch : public hsim_entity {
protected:
sim_port pdim, mdim, pein, swout;
// Routing
int x,y,z;
int dim; // 0=xsw, 1=ysw, 2=zsw
virtual int route(int dest); // Return op no.
int route_dim(int i, int di, int dsz); // Return M_OUT/P_POUT
// Internal blocking
int op_blocked[3][4];
int ip_blocked[3][4];
int ip_dest[3][4]; // Dest op for given iq
int op_ipno[3]; // ip no for given op
int op_ipvc[3]; // ip vc no for given op
void ok(int i, int v); // Send OK to ip/vch
// Virtual channels - each is an array of 8 flits.
vc *vchan[3][4];
void break_link(int input_no, int vc_no, int op);
void make_link(int input_no, int vc_no, int op);
// Conflict resolution for input
int ip_pri;
int vc_pri;
int ip_dist( int ip ); // distance of ip from pri
int vc_dist( int vc );
void rotate_priorities();
void resolve_conflict(int&i1,int&vc1,int i2, int vc2);
sim_port* get_op_port(int i);
sim_port* get_ip_port(int i);
int get_op_no( sim_event &ev );
int get_ip_no( sim_event &ev );
void send_qe(queue_elem &qe, int dest);
void wait_for_msg();
void swallow_clocks();
void make_clock();
void recv_input_msgs();
void recv_oks();
void forward_flits();
void arbitrate();
void handle_msgs();
void dump_state();
public:
cswitch(char*n,
sim_port *pein_i, sim_port *pdim_i, sim_port *mdim_i,
sim_port *swout_i,
int x_i, int y_i, int z_i, int dim_i );
void body();
}
Building the models did provide useful insight into the low level behaviours of these networks, and led to a new approach described in the next section of this report.