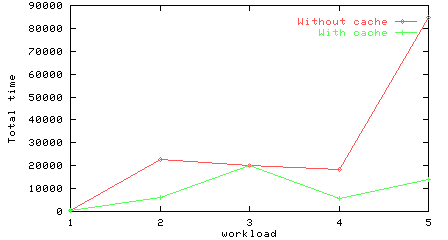
Total time for the workloads on a bus, with and without a cache.
The model and workload are separate programs, compiled into separate libraries in separate directories, and only linked together at the end to produce an executable simulation program. This rigid division of the two allows the mix and match process. For example, a bus model and a random workload could be combined using:
CC bus.a random.aand the bus model with a memory bank saturating workload using:
CC bus.a memsat.aThe important features of the testbed are:
The workload is called from the model, the interface being in the functions:-
void init_workload(p_fn &mf); void do_workload( int argc, char **argv, int index, int nprocs );init_workload must be called first by the model; it reads in the global parameters from the input.params file.
The workload is chosen using the workload parameter set in input.params, example values being:-
A workload-specific function to perform memory operations may be provided in mf, for example the cray model includes a memory unit which responds to cray specific memory operations.
The workload drives the model using the function:-
void do_cmd(int index, int cmd, int pno, int addr, int size, int *data);
This performs one of the following commands:-
| Command | Explanation |
|---|---|
| SEND_C, RECV_C | Send and receive messages between processors. |
| READ_C, READ_R | Read memory Command, and Response. |
| WRITE_C | Write Command. |
| TST_SET_C | Read-modify-write Command. |
| PROC_C | Local processing Command. |
| USER_C | User defined Command. |
| USER_R | User defined Response. |
Note that messages to memories are Commands (such as read requests); messages in response to commands are Responses.
Memory units may be driven using:-
int read_mem(int index, int a); void write_mem(int index, int a, int val); void do_mem_cmd(int index, int cmd, int pno, int addr, int size, int *data);
Workload specific timings may be obtained using:
double get_time(int index);And results may be placed on the trace file using:-
void put_result(int index, char *string );
1024 (cache_size) 10 (cache_access_time) 5 (cache_tag_access_time) 10 (cache_upbus_time) 100 (cache_downbus_time) 1 (cache_upbus_width) 1 (cache_downbus_width) 2 (cache_assoc) 4 (cache_blk_size) 1 (cache_tagmems)
The simulation code accesses these parameters using code like:-
double cache_size = get_int_param(0,"cache_size"); double cache_access_time = get_int_param(0,"cache_access_time");
The workload is chosen using the workload parameter set in input.params.
for (i=0; i<nmsgs; i++) {
pno = i % nprocs;
do_cmd(index, SEND_C, pno, addr, size, data);
}
The standard Cray T3D network operation PE_noncache_rd is used.
The memory is specialised to deal with the different remote memory operations supported by the Cray, i.e.:
enum {
PE_noncache_rd, PE_noncache_rd_res,
PE_wr_1word, PE_wr_1word_res,
PE_cache_rd, PE_cache_rd_res,
PE_wr_4word, PE_wr_4word_res,
BLT_rd_1word, BLT_rd_1word_res,
BLT_wr_1word, BLT_wr_1word_res,
BLT_blk_rd, BLT_blk_rd_res,
BLT_blk_wr, BLT_blk_wr_res,
pfetch_rd, pfetch_rd_res,
f_inc_rd, f_inc_rd_res,
f_inc_wr, f_inc_wr_res,
swap, swap_res
};
for (i=0; i<nmsgs; i++) {
pno = index % memmodules;
do_cmd(index, READ_C, pno, addr, size, data);
do_cmd(index, PROC_C, 0, 0, 1, NULL);
}
for (i=0; i<nmsgs; i++) {
pno = index % memmodules;
do_cmd(index, READ_C, pno, addr, size, data);
do_cmd(index, PROC_C, 0, 0, 1, NULL);
}
Followed by
/* No contention mutex */ /* Non local mutex with contention */ /* Cross process mutex with contention */ /* Mutex trylock */ /* No contention reader lock */ /* No contention writer lock */ /* Reader trylock */ /* Writer trylock */ /* No contention semaphore */ /* Semaphore trywait */ /* Reference global variable */ /* Get thread specific data */
The mutex tests are performed with the code:-
// Get lock
do {
val = 1;
do_cmd(index, TST_SET_C, mp, ma, 1, &val);
tries ++;
} while (val==0);
// process
do_cmd(index, PROC_C, 0, 0, 5, (int*)"got lock");
// Release lock
do_cmd(index, WRITE_C, mp, ma, 1, &zero_val);
The overall parameters and default values are:-
| Value | Parameter name |
|---|---|
| 1 | interconnect |
| 1 | usecache |
| 10 | nprocs |
| 10 | cmd_startup |
| 5 | cmd_perword |
| 100 | bus_startup |
| 10 | bus_perword |
| 100 | mem_startup |
| 100 | mem_perword |
| 1024 | cache_size |
| 10 | cache_access_time |
| 5 | cache_tag_access_time |
| 10 | cache_upbus_time |
| 100 | cache_downbus_time |
| 1 | cache_upbus_width |
| 1 | cache_downbus_width |
| 2 | cache_assoc |
| 4 | cache_blk_size |
| 1 | cache_tagmems |
| Parameters | Bus hold time. Bus time per word. Applies to all commands. |
| Operations |
Always holds for Bus hold time.
|
| Behaviour | Acts as a passive router of commands. Holds for a message dependent time, then passes the command on. Only one command may occupy the bus at a time. Requests dealt with on a FCFS basis. No actual arbitration or priority apart from this. |
| Parameters | Bus hold time. Bus time per word. Applies to all commands. |
| Operations |
|
| Behaviour | Acts as a passive router of commands. Waits for each command to arrive, passes it on a message dependent time later. Never actually holds itself. |
| Parameters | Bus hold time. Bus time per word. Applies to all commands. |
| Operations |
|
| Behaviour |
Acts as an array of crossbars. Events from processors or memories are passed into the internal network of switches. When they emerge, they are sent on to the appropriate processor or memory.
|
| Parameters |
|
| Operations |
Always holds for Command hold time.
|
| Overall operation |
User code is in:
void do_workload( argc, argv, index, nprocs ); This calls: void do_cmd(int cmd, int pno, int addr, int size, int *data); do_cmd holds for the command hold time, then behaves as described in the operations section above. All hold delays are modelled as startup plus time per word. There is no extra delay on a read request returning.
|
| Parameters |
|
| Operations |
Always holds for Memory hold time.
|
| Overall operation | Holds for Memory hold time. Performs operation, returns instantly. For user commands, provides read and write methods which operate instantaneously. User delays may be inserted by calling the hold method. |
| Parameters |
|
| Operations |
Performs tag look up.
|
| Overall operation |
Waits for requests from processor (``up''). Looks
up tags. If hit, returns data. If miss, sends request
down. Also receives invalidate requests from down. Holds for calculated time, then sends.
|
Total time for the workloads on a bus, with and without a cache.
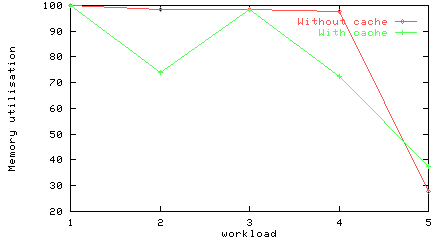
Memory utilisations for the workloads on a bus, with and without a cache.
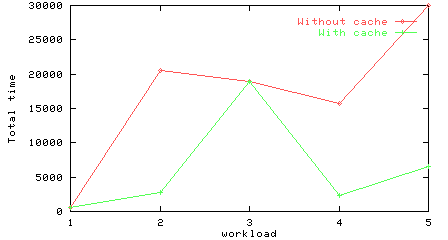
Total time for the workloads on a crossbar, with and without a cache.
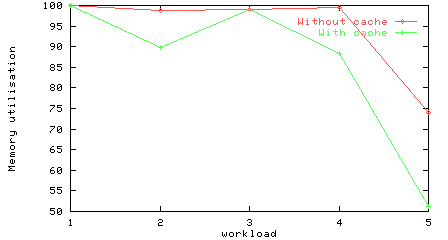
Memory utilisations for the workloads on a crossbar, with and without a cache.
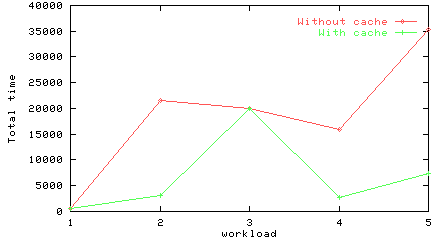
Total time for the workloads on a multistage network, with and without a cache.
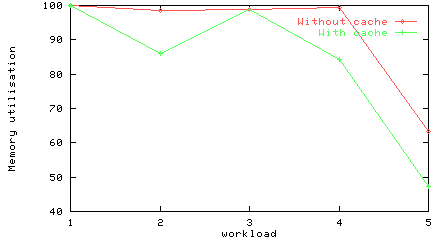
Memory utilisations for the workloads on a multistage network, with and without a cache.
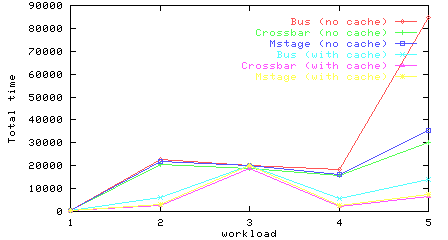
Total times for all workloads and networks, with and without cache.
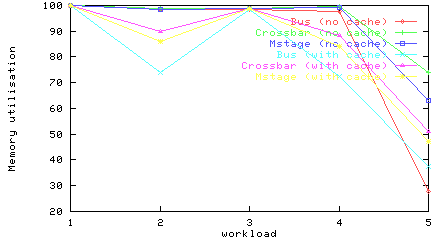
Memory utilisations for all workloads and networks, with and without cache.
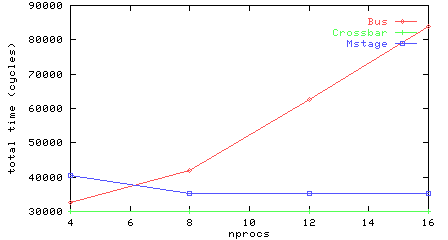
Total time for variable numbers of processors and the same workload (no 5). Note the bus time grows linearly with number or processors, the crossbar time is constant, and the multistage network is slower for 4 processors than 8, 12 or 16. This apparently anomalous result is because of increased contention in the 4 processor case.
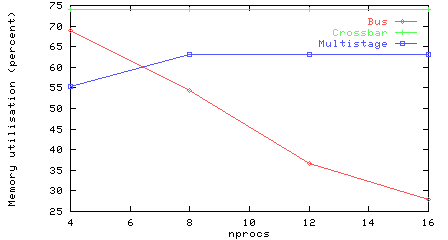
Average memory utilisation vs number of processors. Note the falloff for the bus, as the contention means that the memory units are not kept busy. Memory utilisation remains constant for the crossbar and multistage network (apart from the special case at 4 processors).


Key for timing diagrams.
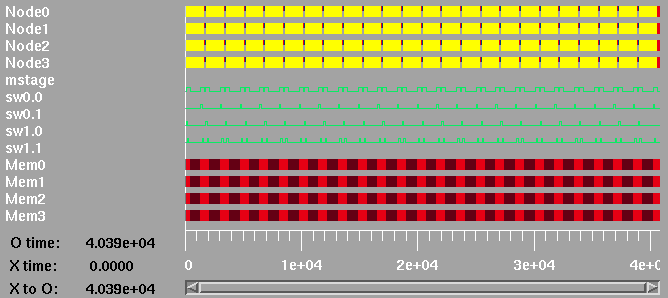
Top level timing diagram for 4 processors on a multistage network.
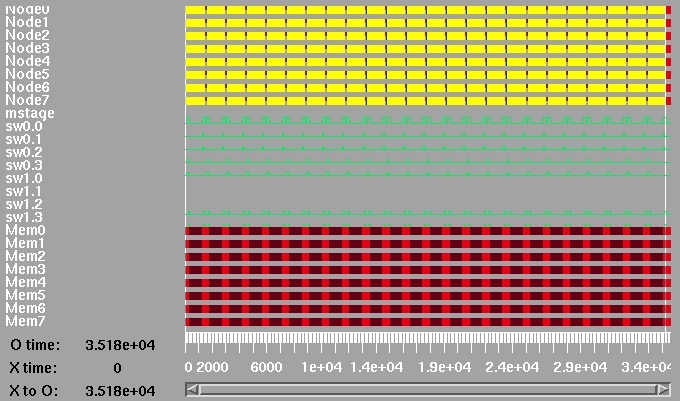
Top level timing diagram for 8 processors on a multistage network.
The next two diagrams show the detail of the first few transactions. Note that the transaction time for the 8 processor case is shorter than for the 4 processor case as the traffic is split between two switches.
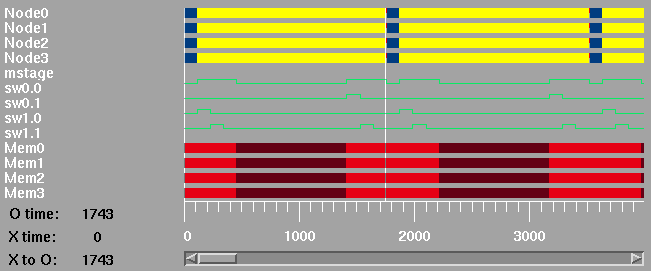
Top level timing diagram for 4 processors on a multistage network.
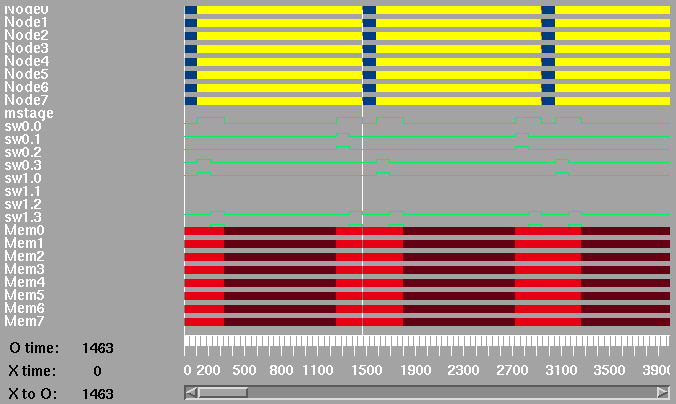
Top level timing diagram for 8 processors on a multistage network.