Division of Informatics
A Web Interface for HASE
WebHASE at its most basic is a system allowing users to access the HASE discrete simulation environment over the Internet. It fulfils a need by ICSA to allow students easy access to the HASE simulations, without requiring a large amount of effort while restricting the modifications that they can make the to models. WebHASE also allows the HASE system to be integrated into the ILSE for Computer Architecture, bring closer the vision of an interactive virtual textbook on the subject.
The WebHASE system makes use of three key Internet technologies: applets, servlets and XML to produce a robust distributed multi-user system. The applicability of these technologies in the field of simulation and the interesting functions they provide are discussed. The use of servlets to generate XML, which is subsequently read by an applet, is unusual at present and its ramifications are also explored.
Table of Contents
1.1 HASE, ICSA, ILSE and WebHASE
1.2 Web-based simulation and WebHASE
4.3 Data Format and Communication
7.2 Impacts on Web-based Simulation
7.3 Implications for Using Complicated Systems
over the Internet
Appendix A. Requirements Specification Document
Appendix B. Users Guide to WebHASE
Appendix C. Administrators Guide to WebHASE
Appendix D. XML Document Type Definition
1 Introduction
In introducing the project there are two contexts in which WebHASE should be placed, as part of the HASE system, and as a web-based simulation. This is because as well as providing a new facet to the HASE system by allowing remote access, WebHASE represents a new approach to web-based simulation in terms of what is achievable, the technology used and the design of such systems.
1.1 HASE, ICSA, ILSE and WebHASE
The HASE system provides an integrated development environment for the design and simulation of discrete event simulation models, in particular computer architectures. At the time of writing, the HASE system has a variety of simulation models, including the DLX RISC architecture, the Stanford DASH Cluster and the Tomasulo Algorithm. The system is used as a research tool and for teaching, particularly MSc students in Edinburgh and Livingston. The system is constantly being updated, as its functions are enhanced and as architectural models are improved, meaning that the distribution and maintenance of the system is a challenge and is the main hurdle stopping the system from being used more widely. To use the system, the user must have a variety of software installed locally in addition to the HASE system. The system is a large body of work and so represents a significant piece of Intellectual Property owned by the University. There are also a number of disparate versions of the system running on different UNIX environments, including Solaris and Linux. The WebHASE system allows any user with an Internet connection and a login ID to use the HASE system without any of the problems associated with it, enabling its use as a teaching tool with minimum support cost.
The Institute for Computing Systems Architecture (ICSA) at the Division of Informatics, University of Edinburgh has also been developing the Integrated Learning Support Environment for Computer Architecture (ILSE). This is an online textbook on computer architecture including interactive demonstrations using applets and SimJava, an architectural simulator written in Java. ICSA requires a system allowing HASE to be used externally, possibly as dynamic demonstrations as part of ILSE, while retaining the IP that it represents within the University. The WebHASE 4th Year Honours project fulfils this need by allowing users to run HASE simulations remotely through their web browser. This simultaneously removes the need for users to have their own copy of the entire HASE system and protects the IP that it represents.
It is hoped that the WebHASE system will be used as the standard interface to HASE simulations in the future, as it promises to provide a far superior interface and user experience than the current QuickTime user interface. It will also allow the University of Edinburgh to easily license the HASE technology to other institutions as a teaching aid. Furthermore, the WebHASE XML Document Definition Type is sufficiently general that the WebHASE applet could be used as an interface for other discrete simulation systems, reducing the development cost of creating new internet front-ends to “legacy” simulation systems.
1.2 Web-based simulation and WebHASE
The area of web-based simulation originated as a number of papers given at a popular session on the subject at the 1996 Winter Simulation Conference, and has been an area of active research since. One of the most quoted papers from the conference is Paul Fishwick’s [[1]], in which he described the effects of the internet upon the field of simulation, in particular identifying web-based access to simulation programs and distributed modelling and simulation.
The majority of interest since has centred on distributed simulation, and in particular its use in military war games, where a large number of humans (sometimes over 1000) interact with a distributed simulation model[[2]]. Various interesting technologies, such as CORBA[[3]], Remote Method Invocation[[4]] and Java servlets, have been used to allow the simulations to be distributed. It is without doubt an exciting research area and the main focus of the general simulation community.
In comparison, research into web-based access to simulation systems has been sparse, especially its integration with so-called “legacy” systems (which is used to describe any system not written in Java). Web-based access to simulation programs has been equated with CGI scripts running simulations on servers and stands alone Java applets being used as a means to publish a simulation. For this reason, web-based access has largely been ignored as a research area as it is assumed to be a simple exercise in software engineering. Our experiences with exporting the HASE system onto the internet as WebHASE has shown that this is definitely not the case and brings to light a number of issues with the currently favoured Java Technologies, and more general problems in using the internet as a medium for allowing access to simulation systems. We describe one possible solution to the problem in the hope that future modellers intending to export their discrete simulation environment onto the web will find it useful.
A simple survey of web-based access to simulation systems will show that apart from those that do not work (a large proportion), most are either completely server side CGI scripts or client side applets. Both these techniques have limitations. CGI scripts lack interactivity, as they force the user to interact with the system through the use of HTML forms and require that the simulation output data is some sort of document that can be displayed as HTML. They are generally written for a single simulation model, use up server resources and have problems handling concurrent users. Applets, in comparison allow a much higher level of interactivity, use up the client’s resources and handle concurrency. However, they require that the simulation model be written in Java (not as much of a problem given the interest by modellers in Java), and have security restrictions placed upon them that limit their flexibility as a simulation environment (see 4.1.1), the most important being that the user cannot use local simulation stimulus files, or have simulation results written to local storage. They also suffer from the problem of being designed for a single simulation model, usually a simple one, as Java Applets use up more resources than simulations written in C, say. The combination of these restrictions means that Java Applets are inappropriate as the basis for a large-scale generic simulation environment. Note that these restrictions do not apply to Java applications in general, and Java is being used as a distributed simulation environment with a great deal of success.
The WebHASE project has shown that combining applets, via a structured data format (XML), with a more modern server side technology (Java servlets), allows general access to a discrete event simulation system (HASE). Furthermore, it has also shown that this improves the accessibility and usability of the simulation environment by model users, such as students.
2 Synopsis of Results
The WebHASE system was successfully engineered during the time span available and fulfils the Functional Specification (see Appendix A below). The system works with the current set of HASE models, including the DLX RISC architecture and the Stanford DASH Cluster. Further models, including the Tomasulo algorithm are being developed and the WebHASE system is expected to work with them as well. Figure 1 below shows the WebHASE applet running the DLX HASE model.
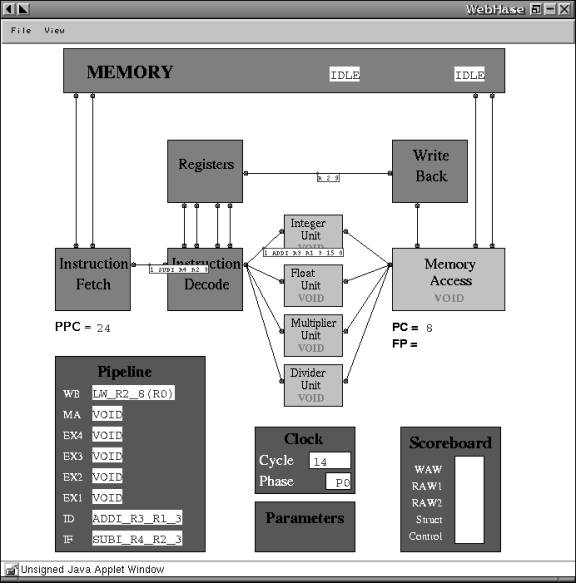
Figure 1 WebHASE Applet window, showing the DLX model
A number of challenges for web-based access to simulation systems were discovered. They are summarised below along with the solutions that were used within WebHASE:
· Applets are kept in a virtual sandbox and are not allowed to access local data, a problem if we intend to allow users to use their own simulation stimulus files. By combining the applet with html forms going to the server, users are able to upload their own simulation stimulus files or User Arrays.
· The request/reply process of the simulation model being executed and results returned to the user must be as quick as possible, to keep interactivity up and to avoid any timeout problems which might otherwise occur. While to some extent this is an issue for the HASE model rather than the WebHASE system, the interpretation, conversion and transmission of simulation data must be as fast as possible. Through a process of experimentation with the XML data format, and the use of line by line file interpreters rather than parsers, the servlets were kept as fast as possible, keeping the server reply time to a minimum.
· Multiple users must be able to use the system concurrently, with each user being kept completely independent of others. Making use of the session level scope feature of Java servlets and keeping a separate instance of the simulation model for each user achieves this.
· By having a copy of the HASE model for each user, system resource issues arise. When users leave the simulation environment, all traces of their simulation session must be removed. WebHASE instances no longer in use must be deleted when the user is finished. This is achieved by using a Delete servlet that is accessed when the system exits.
· Client failure or uncontrolled exiting of the applet can cause orphan WebHASE instances on the server, using up resources. By carefully controlling the ways in which the client can leave the system, through the use of JavaScript and including checks by servlets being executed by other clients, these problems can be avoided.
3 Design Methodology
Though the WebHASE project is a Computer Architecture project, it bears more resemblance to a standard software engineering project. This system is designed for use by future students as a teaching aid and researchers as the standard interface to the HASE system. This means that the project has a clearly defined set of customers and aims. For this reason, a standard development process was followed, with requirements capture, specification, design, implementation, testing and integration.
The first task undertaken was to draw up a Requirements Document that was used to help clarify the aims and deliverables of the project. This can be found in Appendix A. This was written by the author and checked by the customer, the Project Supervisor!
From this the architecture of the system was determined. This proved to be fairly straightforward due to the requirements and technological limitation. The overall architecture was already defined, requiring a client server system operating over the Internet. Java applets were the only possible choice for the front end, and Java servlets the easiest way to gain the session level scope required by the system. XML was decided upon as the data format for communication between the two parts of the system so as to give a clear interface between the front and back ends of the system, and also to educate the author.
The system was then designed and implemented in three separate phases. Firstly the applet was designed and coded in parallel with the XML Document Type Definition. This enabled hand-coded XML documents to be used as input into the applet. An XML generator was then written and used to generate XML files from simulations. The Java servlets were developed and the XML generator incorporated.
The finished system was then integrated with the Division of Informatics web servers. Further changes were made due to user testing by Roland Ibbett and students on the MSc in Systems Level Integration course at Livingston.
4 Technology Choices
While the requirements document allowed for the use of various core technologies, it was written with the technologies listed above in mind. To some extent this was due to lack of choice, the particular preferences of the author and supervisor, and partly because the given technologies work well together. This section explores the choice of technologies and the abilities and restrictions that they involve.
4.1 Client Side System
The client side system had to have a number of attributes. It was required to provide a high level of interactivity to allow the manipulation of the simulation and be accessible over the Internet. There were four different choices, static HTML/XML with JavaScript and style sheets, client code that had to be downloaded and run outside of the environment of the web browser, a Java applet or a propriety Microsoft applet.
While it would be possible to write the system in such a way that the user output was HTML or XML, this was obviously not a useful solution, and not what HTML or XML is designed for.
A downloadable client application would provide an acceptable level of interactivity but is too close to simply downloading the entire HASE system to be acceptable. In addition it would not allow easy integration into ILSE, and required a greater level of support.
A proprietary Microsoft Applet would connect easily with Microsoft Application but obviously not with a system running Linux. In addition, it would restrict clients to using a Microsoft platform.
Java Applets gave an acceptable level of interactivity, coupled with cross-platform support and easy integration within the ILSE. However, there are various constraints that must be taken into account when using them as the client to a simulation system. Broadly, these are Data Access, User Interface, and Browser Control.
4.1.1 Data Access Restrictions and Solutions
Java Applets have an appropriately restrictive security model, which allows users to download applets secure in the knowledge that malicious code cannot damage their system. While it is possible to create trusted applets with more freedom, this requires various certificates and changes at the client side, something that was deemed infeasible for a system to be exported for anyone to use.
Java Applets are unable to access any system resources directly. They cannot read or writes local files and can only make network connections with the IP address from which they are downloaded [[5]]. While very effective from a security point of view, this creates a problem for distributed simulation system designers. One of the functions of most distributed simulation systems is to allow the remote user to use their own (local) input files within the applet as stimulus for the simulation. Obviously, this requires the applet restrictions to be circumvented. One strategy is to provide standard input that the user can view and modify, by typing or cut/paste. This works well for systems where the input data will vary little from a standard template, in other words where a little change in the input data creates a large change in the simulation.
The applet local data restriction can also be circumvented by the use of html and servlets. The <input type=”file”> tag can be used to upload files from a local machine to a server, as part of a standard HTML form [[6]]. The server receives the contents of the file and processes it appropriately. This cannot really be used from within the applet, however; and so can only be used for initially setting up the stimulus files on the server.
A possibility that is complimentary to both the above approaches is keeping a long term “virtual workspace” on the server that the user accesses when he wishes to use the system. Simulation stimuli are kept from session to session for later reuse. Obviously this strategy is little different from providing a remote user with a telnet connection.
The other system access restrictions were less onerous, but did require that the simulation system be located at the same location as the web server. This is because the applet is only allowed to access data from the same domain from which it was loaded. In other words, if the applet is loaded from http://tweed.dcs.e.ac.uk:8082, then all files it requests must also be located there, including .gif files, and servlets.
4.1.2 User Interface and JRE 1.1
The major restriction in using standard Java applets is the use of the Java AWT instead of the more modern Swing GUI components. Java AWT (Abstract Window Toolkit) makes use of native widgets on the host Operating System to build up a GUI and was developed early on in the history of Java, in version 1.1. Swing, in comparison, is completely Operating System independent, much more lightweight in terms of resources, more powerful and easier to use. It also looks nicer but only became part of the standard JRE in version 1.2.
Unfortunately the majority of browsers do not support Swing, as they only implement JRE version 1.1. This can be circumvented by the use of a Java Plug-in. This removes the onus on the Browser to support Java, and instead encapsulates the Java Runtime Environment within a Browser Plug-in in the same way that VRML and Quick-time movies are supported[[7]]. However, while a good solution in principle to the problem, it still requires the user to download an additional piece of code, and lacks general support. It might also be possible to avoid the problem by loading the Swing package from the server along with the applet, but this would entail a significantly increased download time for little benefit. Given that the user base of the WebHASE system is students, who may be unable to change their client computer settings, it was deemed inappropriate to use the Java Plug-in as anything other than a last resort if it was impossible to make the system work as a standard Java applet. A Java Plug-in option has been included within the system to allow users of browsers with insufficient Java support (such as Internet Explorer) to access the system.
The result of using JRE 1.1 is that a variety of powerful Swing abilities, such as coloured text boxes, and a sophisticated event model cannot be used along with additional classes and methods that only became available in JRE 1.2. While the majority of these problems can be worked around, it is important that the system is developed with these problems in mind, especially if the classes are being compiled within a 1.2 JDK.
4.1.3 Browser Control
The third restriction in using Java Applets is that the browser controls the applet’s activities to a certain extent. The applet runs within a thread controlled by the browser, and its initial window within the browser is quite restrictive. The easiest way to get around this is to run the majority of the applet within a new window apart from the browser window itself. This appears to allow greater control of the applet along with allowing a bigger window to be used.
4.2 Server System
In comparison with the choice for client side system, the number of server systems capable of fulfilling the requirements is fairly large. There were two main consideration in choosing a server technology. Firstly, the system had to be able to communicate with the client system over the Internet. Secondly the system had to be capable of running the HASE system on a Linux server. This second requirement effectively split into two on further study. It was obvious that, from a simplicity point of view, it was desirable that the entire server system, including the HASE system, should reside on a single machine, reducing system administration problems. It also became obvious that each instance of the HASE system had to be unique, while still mapping to a single user during the course of a WebHASE session. This equated to the system requiring session-level scope, with some state being maintained by the server between client requests.
There appeared to be a clear request/response dynamic between the client and server, with the client requesting a new simulation and the server responding with the results of the simulation. In addition, the number of request/response pairs from a given WebHASE session was expected to be fairly low, maybe one every 5 minutes, as the user was expected to study a simulation before requesting a new one. It is also desirable that the client applet is able to request static simulation information, for the purposes of demonstrations.
The only technologies adequately fulfilling these requirements are CGI scripting and servlets, as technologies such as CORBA and Remote Method Invocation, as well as being possibly more complicated to deploy, lack the ability to have easily available static data. CGI scripting is fairly basic from the perspective of reliability and efficiency and would require some work to achieve the session level scope required. Servlets take a much more managed approach to supplying a service, aiming for a more efficient system and allowing server code access to a greater variety of functions.
Java was the obvious choice of language for the servlet system as it is well supported and matches the choice of client applet. A large variety of Java servlet systems are available, from IBM Websphere Application Server [[8]], a large system integrated with various other IBM products, to Apache Jakarta TomCat [[9]], and Resin from Caucho Technology, Inc [[10]]. There is a strong correlation between the length of name of a servlet system and the size and resources required to run it, with Websphere requiring not only a powerful machine but also the installation of DB/2 or other database product.
The great advantage of Java servlets over other technologies is that by complying with the standard servlet API, the same Java servlet can be used with any servlet engine requiring no change. So, the author was able to run IBM WebSphere on his home system while being confident that the same servlet byte code would work on any servlet system used in the University.
The servlet system chosen for use by the University was Caucho Technologies’ Resin, which is lightweight, very fast and freely available at www.caucho.com. This choice was made after attempting to use other systems without success in integrating them within the departmental Web servers.
4.3 Data Format and Communication
Given the choice of applets and servlets for client and server respectively, the communication between the two was already defined as being HTTP over TCP/IP. However, the format of the data that was to pass between the two was undefined. It was desirable that this should be defined clearly early on, as this would allow a clear interface between the client and server so that they could be developed independently to some extent. It was also required that the format be human-readable to allow easy debugging and the hand-generation of data for testing the applet. To fulfil this requirement the data would have to be in some textual format, rather than being a serialised Java object, for example.
Initially it appeared that wrapping all the simulation data within a reply and making the applet parse it would be an adequate solution. However, this forced the client to do a lot of work, and exposed some of the HASE system’s IP. A better solution was found in converting the simulation data at the server end into a structured format that could easily be converted into the internal model that the applet would use to replay the simulation. The obvious choice for a structured data format was XML. This had the added advantage that various Java parsing tools are available allowing the rapid development of the data generator and parser. The major tools used were IBM’s XML4J package and the Apache group Xerces project. A further choice was to transmit the XML as a textual format, as opposed to a serialised Document Object Model, which would be faster. This was done because a textual format is easier to check and allows static files to be used as demonstrations of the system.
5 System Design
Having decided upon the technologies to be used in implementing the project, the design of each component could be undertaken. This section considers the design of each component in some detail.
Figure 2 shows the principal data flows through the system and the various components that make it up. Below is an overview of the actions and interconnections of each component, following the flow of a WebHASE session. The numbers refer to Figure 2 below.
1. The user enters the system in one of two ways. They can either select a simple link that will bring them straight to the applet with default input stimulus, or they can upload their own stimulus files using an HTML form. While the latter method appears to offer the user more flexibility in running the system, it was found that it confused users, as they were unable to upload their own stimulus files at any other point within the system. New users did not know what files were expected, and support for this method within the servlet API was inadequate. For these reasons a simple URL is now used in preference. WebHASE parameters are also included, but are hidden from the user.
2. The Initiate servlet creates a new WebHASE instance on the server based on the parameters submitted by the client, including the HASE model to execute. It also forwards the user to the WebHASE applet page, which is loaded by the client.
3. The WebHASE applet requests a new simulation from the Execute servlet, submitting User Arrays, the stimulus for the simulation.
4. The Execute servlet writes the submitted User Arrays to the HASE instance, which then runs the simulation. It then generates an XML document from the results, which it sends to the applet.
5. The WebHASE applet displays the new simulation, allowing the user to play through it with animation, and explore the simulation results graphically.
6. The user can make changes to the User Arrays and request a new simulation, in which case, the flow returns to point 3.
7. The user can exit the WebHASE applet, in which case the client is forwarded to a new HTML page, after a call to the Delete servlet has been made.
8. The Delete servlet is responsible for cleaning up after the user. It removes the WebHASE instance and any cookies used by the system.
Each of the components is considered in greater detail below.

Figure 2 Data Flow
5.1 HTML Design
Within the WebHASE system there are two critical HTML pages. The first is the HTML form that can be used to starts the WebHASE system. This must identify the model to be used, the files that should be included in the HASE instance and any user arrays to be uploaded. The second HTML page is simpler, being used to control the applet.
In addition to these two HTML pages, a simple URL on a web page can also access the WebHASE system. This link makes use of the GET HTTP method, where the parameters for the servlet (or CGI) call are appended to the end of the URL, with encoding being used to avoid problems with the HTTP request. As one might expect, the number of parameters required to start the WebHASE system is quite large, so a tool has been written as part of the eduni.hase.webhase.servlet package to generate URLs easily. Details can be found in Appendix C.
5.1.1 Initial Form
As has been discussed previously, the form method for accessing the WebHASE system has been replaced by a much more elegant URL based method. With the exception of uploading the User Arrays, both methods serve the same purpose, calling the Initiate servlet with the parameters necessary to set up a WebHASE session. A description of the operations of the form method is given below, to identify the parameters identical to those of the URL method and to outline the use of this method for future systems.
The initial HTML form identifies to the server which simulation to run and allows the user to upload any User Arrays. The former is achieved by using a number of hidden fields. By changing the values of these hidden fields, the administrator can cause different simulations to be run. This is an important feature as it means that the system can be administered without requiring multiple servlets or applets, or the recompilation of either for the addition of new simulations. The hidden fields are detailed below.
· filelist. This is the UNIX path to a list of the HASE files that must be copied to make up the HASE instance. This includes the .edl, .elf and HASE executable files. The list file is a simple \n delimited list of full pathnames to files.
· modelname. The modelname identifies the HASE simulation model name, which is used to identify the correct .elf and .edl files.
· appleturl. This is used to redirect the browser to the correct applet page.
· gifurl. This is the URL where all the .gif files used as icons can be found. Due to data access restrictions on applets, this must have the same host name as the servlets themselves.
· haseexec. Finally, the HASE executable must be identified.
The other main element in the form is a number of file upload tags. The file upload tag must rate as the least used HTML tag. It is identical to other HTML input tags in format, but with the type set to file. The tag places restrictions on the form’s transmission type and method [[11]]. The tag, and the view it presents to the user are shown below.
<input type=file name="MEMORY.instr_mem.mem" size=25>
![]()
The type parameter simply identifies this input tag as a file upload one. The name parameter is used by the servlet to determine the name of this file within the HASE system. The size parameter identifies the size of the text box that should be displayed by the browser.
When users click on the Browse… button, they are presented with a typical file open dialog that allows them to select the file that they wish to upload onto the server. The name parameter within it is used by the servlet to identify the name of the file that the local file contents should be written to within the HASE instance. This uploading system is obviously extremely useful for user input to online simulation systems, allowing users to design stimulus files locally and upload them to the simulation system. However, as noted below (5.4.1), limitations within the servlet API mean that this feature is not as well supported as it might be. The Browse button also defaults under Netscape to only show .html files. In addition, presenting a set of input boxes without any instructions is unfriendly to new users, especially if they require the user to have some knowledge of the system to use.
5.1.2 Applet HTML Page
The Applet HTML page is the location to which the Initiate servlet re-directs the client browser after generating the new HASE instance. It is defined in the appleturl hidden input type. The applet HTML file can contain anything required, such as model or user information. The important element of the html page is the applet tag. An example applet tag is given below.
<applet code="eduni/hase/webhase/LayoutApplet.class" archive="xerces.jar" width=1 height=1>
<param name="xmlurl" value="http://tweed.dcs.ed.ac.uk:8082/servlet/Execute">
<param name="killurl" value="http://tweed.dcs.ed.ac.uk:8082/servlet/Delete">
<param name="returnurl" value="http://www.dcs.ed.ac.uk/home/hase/webhase/">
</applet>
Figure 3
HTML code for the WebHASE Applet
The code tag identifies the WebHASE applet class. The archive="xerces.jar" is required. It identifies the Apache group Xerces package that includes the XML parser used by the applet.
The xmlurl parameter shows the location from which the applet will attempt to get the simulation data from. This can be either the Execute servlet (as in this example), or the location of a static XML file. This is used to run the demonstrations, as the applet retrieves the same XML file no matter what changes are made to the Data Arrays.
The killurl parameter is the location that will be retrieved when the applet exits. This is different from the location to which the applet will point the browser after quitting (see below). Instead this locates the Delete servlet that will be used to delete the HASE instance on the servlet. This is important to avoid filling the server up with old HASE simulation instances, especially if a simulation fails and creates a core.
The returnurl parameter gives the location to which the applet will point the browser when it exits. This is important for two reasons. Firstly, the Initiate servlet re-directs the browser to the applet page initially by producing HTML Meta tags. If the user presses the back button after exiting the applet, the browser will bounce back to the applet page, forcing a reload of the applet. Secondly, the browser may reload the applet by mistake. By sending the browser to a safe page, such as the WebHASE homepage, a questionnaire on the HASE system, or licensing information, the system avoids these problems.
5.2 Applet Design
The design of the applet had to take into account two requirements. Firstly, the applet had to keep a model of the simulation internally which could be viewed and animated. Secondly, the system had to support the retrieval of simulation data from the servlets to build up this model.
To this end four separate packages were created. Figure 4 shows the associations between the different packages. sim is the eduni.hase.webhase.sim package, which contains the model of the simulation to be viewed. This is created by eduni.hase.webhase.xml (xml) and displayed by the viewer (eduni.hase.webhase.viewer). The animation of the simulation is controlled by eduni.hase.webhase.anim (anim).

Figure 4 Package diagram of eduni.hase.webhase
The four packages are described below.
5.2.1 eduni.hase.webhase.sim
This package consists of the model of the simulation used by the applet. Its major component is the recursive SimEntity class which represents a HASE simulation entity. This has associated with it a number of Ports, Parameters, Arrays and Simulation Events. To mimic a compound simulation entity, a SimEntity can also have children consisting of other SimEntities and Nets that connect the children SimEntity’s Ports. Thus the entire simulation can be represented as a single SimEntity. When the simulation is initially viewed, the first level of the SimEntity tree is shown (i.e. the maim HASE simulation entities). Compound SimEntities can be “pushed” into, to show the SimEntities that they contain, allowing the user to view the simulation at any level if detail required.
The various elements of the model derive from java.awt.component, which means that each is able to display itself and all its subcomponents, whether by using a .GIF file as an icon (as SimEntity), or simply by drawing lines, in the case of Nets. This means that the viewer only has to call the paint() method of the top level SimEntity for the entire simulation to be re-drawn.
The SimEntity has SimEvents associated with it. These are either SimStateEvents, which change the state of the SimEntity along with its graphic, or SimParamEvents that simply change the value of a Parameter. All simulation events retrieved from the HASE trace file are created as SimEvents. There are various types of SimEvent. They include changing parameter values (SimParamEvent), sending messages along a Net (NetEvent) and changing the SimEntity’s state and therefore its icon (SimStateEvent).
Within the simulation XML document, a tag identifies a list of GIF files that are used as icons for the SimEntities. The different state icons are cached by the ImageList class when the simulation is loaded, and requested by the SimEntity when its state changes. If the ImageList has the icon already cached, it obviously returns it immediately. If it does not already have the icon for some reason, if the user is playing the simulation before all the icons have been loaded for example, it attempts to load the icon from the server immediately. This speeds up the updating of the animation with a little expense when the applet first loads.
Time within the simulation is split into clock cycles, which are subdivided into a number of stages. So each SimEvent takes place at a given clock cycle and stage. Simulation events for a given SimEntity are stored in a hashtable. Each hash entry is a linked list of SimEvents that take place at the same clock cycle, though possibly at different stages within the cycle. As there are generally few events for a given SimEntity within a single clock cycle, this is an efficient arrangement.
Nets connect the various Ports of the SimEntities together. To allow corners, which are defined within the HASE system, to be shown in WebHASE, Nets are split into one or more straight NetSections. Nets can also have NetEvents which are messages passing along the Net from Port to Port.
 Figure 5
Class diagram for eduni.hase.webhase.sim
Figure 5
Class diagram for eduni.hase.webhase.sim
The SimEntity can contain a number of ArrayEntities. These are HASE arrays of data associated with the entity, and can be viewed by the user. Instead of being viewed within the main window, they are created as separate windows that are viewed using a pop-up menu on the SimEntity. Arrays can have events associated with them as well, ArrayHighlightEvent and ArrayUpdateEvent. These highlight lines within the array and change the value of array entries respectively. Due to limitations on the AWT toolkit (the precursor to Swing that we have to use to stay within JDK 1.1), there are no options for highlighting sections of text. Instead a <= symbol is used. Figure 6 below shows an array entity where the last ArrayHighlightEvent affected the fifth element of the array.

Figure 6 The instruction memory ArrayEntity from the DLX HASE model
ArrayEntities play a critical role in the generation of new simulations. When a user requests a new simulation, all the ArrayEntities become editable. By making changes to the different arrays, the user changes the simulation stimulus. These modified arrays are sent to the server as part of the simulation request and used as stimuli for the HASE model.
5.2.2 eduni.hase.webhase.viewer
The viewer package contains the additional GUI components necessary to view the simulation model. These mainly consist of classes associated with the window in which the simulation is shown, the actual viewer. The viewer is also responsible for the drawing of the simulation. To avoid flicker during animation double buffering is used. This means that instead of clearing the window and redrawing the GIF icons of the SimEntities, followed by the parameters and the Nets, every time a refresh of the screen is required, the new window is drawn to a canvas off-screen and copied into the window in one go. This makes the animation flicker free, and appears to improve the performance of the applet from the client’s perspective, as s/he isn’t aware of the refresh happening.
5.2.3 eduni.hase.webhase.xml
The xml package is used by the applet to convert the XML document that it receives from the servlets into the sim model. There are two main methods provided for parsing an XML document, DOM (Document Object Model) and SAX (Simple API for XML (acronyms within acronyms)).
SAX uses an event model, with methods being called whenever the parser encounters certain tags. This requires less memory than DOM methods, as it doesn’t attempt to build a view of the entire document. It is particularly useful for parsing a relatively small amount of information from a large document, or when the program is interested in the content of the document rather than its structure.
DOM builds up a tree structure in memory, which the system then traverses. This method is more efficient if the user intends to use data from the entire document, and the structure of the data is conserved. For this reason the DOM method was used in preference to SAX for the parsing of the XML document by the applet.
The XML document response from the Execute servlet is automatically built into a Document Object Model (DOM) tree by methods provided by the Apache Xerces package and then traversed to create the SimEntity. The XML DTD (Document Type Definition) was carefully designed to ensure that there was a match between the XML structure and the model it builds (see 5.3 below). This means that the XML parsing is as efficient as possible.
5.2.4 eduni.hase.webhase.anim
The anim package consists of animation controllers and associated GUI components. The animation itself is run in a separate thread from the rest of the applet. This ensures that the user can interact with the simulation while the animation is taking place. The AnimationTimer class loops continually, incrementing the simulation clock used by the applet.
The HASE model produces a time ordered list of events as output from the simulation, with each event taking place at a given time point. There are three clocks in operation within the applet. The first two, the clock cycle and clock stage, are analogous to the timing of events within the HASE system, with each clock cycle being split up into a number of stages at which events happen. The third clock is used to control the animation of messages along Nets. Any messages sent between SimEntities must be completed before the next clock stage. In addition to this, some events take place at the beginning of the clock stage, before any messages have been animated, and some take place at the end.
When the AnimationTimer changes the simulation clock, each SimEntity updates its parameters and state appropriately. The user has control over the animation of the simulation. He can stop, rewind, pause, step through one clock cycle at a time, slow down or speed up the simulation. Figure 7 below shows the playback window, used by the user to control the animation.

Figure 7 WebHASE playback controls on Netscape, Linux
The user is able to change the speed at which the animation takes place, the speed at which messages pass along Nets and the rate at which SimEntities change state. Rather than change the time period between “frames” of the animation, this instead simply reduces the number of frames in which messages are animated between clock cycles. This means that the speed of animation is not limited by the power of the client’s machine, and results in a smoother animation. Unfortunately it means that the animation speed value displayed on the playback controls has no useful value to the user, for example frames per second. The slide controls the number of frames displayed between clock cycles, with the animation displaying fewer frames if the slider is set to the left.
The user is able to stop the animation at any point and move the time-point to an arbitrary point in the simulation. This is an improvement over the standard HASE system in which it is not possible to do this accurately. To achieve this, the clock is stepped very quickly without being displayed. If the simulation is being fast-forwarded, then each clock cycle from the current point to the required one is stepped. If the simulation is being re-wound then it is necessary to reset the simulation, start from the beginning of the simulation and move forward. While this can sometimes result in a slight delay between moving the simulation point and being able to interact with the simulation, it ensures that the simulation is accurate at any given point.
5.3 XML Design
Extensible Markup Language (XML) is a meta-language that enables designers to create their own document formats in a structured way, knowing that the documents will be able to be interpreted easily by other programs. An XML document looks very similar to a more strictly enforced HTML one, but with different tags depending upon the format. The Document Type Definition (DTD) for an XML document defines the structure of the document and the tags and attributes that it has. The WebHASE DTD can be found in.
In designing the XML Document Definition Type there were three main considerations. Firstly, and most obviously, is completeness. The XML DTD has to carry all the required simulation information from the HASE simulation to the applet. Secondly, the DTD has to be quick to generate, as the response to a simulation request from the applet must be completed as quickly as possible to avoid time-out problems. Finally, the XML document has to map easily onto the simulation model that exists within the applet, keeping the code simple and error-free.
For this reason, there is a strong correlation between the hierarchical simulation model within the applet and the XML document. Both are recursive and contain the elements of the simulation, entities, ports, arrays, parameters, nets and events.
<?xml version="1.0" encoding="UTF-8" standalone=”no”?>
<!DOCTYPE webhase SYSTEM “http://www.dcs.ed.ac.uk/home/hase/webhase/xml/webhase.dtd” >
<simulation>
<siminfo>
</siminfo>
<sim base="" name="">
</sim>
</simulation>
Figure 8 An overview of an XML document for a DLX simulation, showing the main tags
A WebHASE XML document is composed of three sections, as is shown in Figure 8 above. First are the general XML headers, defining the document type and the location of the DTD which defines the document format. Secondly, the actual simulation is contained within a set of <simulation> tags. This allows the future possibility of multiple simulations being included within the same XML document. This is not currently implemented but could be used to store multiple demonstration simulations for tuition purposes, allowing the user to select different pre-run simulations that show the effects of, say, increasing the latency of a function unit.
The simulation itself is spit into two separate sections, general simulation information (<siminfo>) and the simulation entities, including their Nets and events (<sim>).
5.3.1 The siminfo XML tag
The <siminfo> section of the XML document contains simulation attributes such as the author of the model, the date and any comments or warnings. It also contains the important <gifurl> tag. This locates the URL where all the .GIF files used as icons by the WebHASE applet to represent the states of SimEntities within the simulation are stored.
<siminfo>
<date>Tue May 15 09:25:16 GMT+00:00 2001</date>
<warning>None</warning>
<comments>Demonstration of the DLX RISC DLX Architecture.</comments> <gifurl>http://www.dcs.ed.ac.uk/home/hase/webhase/models/dlx/bitmaps</gifurl>
<author>Roland Ibbett</author>
<model>DLX_V2.2</model>
<title>WebHASE DLX_V2.2</title>
</siminfo>
Figure 9 The <siminfo> section of a WebHASE XML document
Warnings in the XML document are brought to the attention of the user in the form of a dialog box when the simulation is loaded. This allows error messages from the servlets to be propagated to the user. These might occur if the user has made changes to the arrays that cannot be interpreted by the HASE system. Obviously this relies on the error-reporting system of HASE itself. During the course of the project, the error reporting of the HASE system in general was improved to the extent that this feature was not needed for that purpose (see 7.1.3 below). However, they are used to bring system level problems to the attention of the user, such as simulations not existing.
Comments can be provided as an option if the user wishes to find out information on the simulation by accessing the View - Simulation Info menu item in the applet. This is useful for static information, but not critical to the system. Figure 10 below shows the information window for the DLX demonstration simulation.

Figure 10 Information Window on Netscape, Linux
5.3.2 The sim XML tag
The <sim> tag represents the vast bulk of a WebHASE XML document. It is a recursive format closely following the SimEntity data structure within the WebHASE applet, consisting of Ports, Parameters, Nets, Arrays and children SimEntities. Figure 12 below shows a small example of a <sim> tag. The structure is fairly self-explanatory, with the simulation entity having a number of different states shown by different icons, a parameter with a value displayed at a given location, a number of Port which may have Net’s connected to them, and a number of events that change the state of the entity and the value of its parameters.

Figure 11 The placement of events in the applet data model and XML document.
Where the XML document differs significantly from the data model within the applet is in the location of events within the document tree. Within the data model in the applet these are associated directly with the element that they affect, for example a NetEvent is stored with the Net that it travels on, while a ParamEvent is stored with the parameter that it changes (see 5.2.1 above). Within the XML document events are stored directly following the relevant simulation entity within the events tag (see Appendix D below). Figure 11 above illustrates the difference in placement. This was done for purely pragmatic reasons. All HASE simulation events are written to a single trace file in an unstructured format. It was found that searching the XML document for the simulation entity in which to put an event took a long time, especially for NetEvents, which required the entire XML tree to be searched. In fact, it slowed the generation of XML by a factor of two for a typical DLX simulation. There was much less cost involved in searching a SimEntity tree for a Net in the Applet, as the actual size of the tree is smaller as we are dealing with an entire SimEntity as a leaf rather than a single tag. As it appeared to have little effect on the interpretation of the XML by the applet, it was decided to put all simulation events at one location within the sim tag. This also had the benefit of increasing the human readability of the XML document.
<sim base="instr_fetch" name="INSTR_FETCH">
<simattributes initialstate="IF_VOID" x="70" y="270">
<params>
<param display="value" name="PPC" x="50" y="86"/>
</params>
<states name="cur_state">
<state name="IF_VOID">
<img src="instr_fetch.gif"/>
</state>
<state name="IF_BUSY">
<img src="instr_fetch_busy.gif"/>
</state>
</states>
<arrays/>
</simattributes>
<ports>
<port distance="25" name="to_memory" side="TOP"/>
<port distance="20" name="to_instr_decode" side="RIGHT"/>
</ports>
<nets/>
<children/>
<events>
<stateupdate stage="0" state="IF_VOID" time="0.000000"/>
<paramupdate name="PPC" stage="0" time="0.000000" value="0"/>
</events>
</sim>
Figure 12 The <sim> section of a WebHASE XML document
5.4 Servlet Design
Three separate tasks were identified for the Java servlets on the server. Firstly, a new copy of the HASE system has to be made for the client on the server. Secondly, the HASE system must be executed using the given user arrays. Finally, on leaving the system the HASE instance must be deleted. It was obvious that these should be implemented as three different servlets, Initiate, Execute and Delete. The three different servlets are discussed below.
5.4.1 Initiate
The Initiate servlet is used to create a new instance of the HASE environment for the user. The user’s HASE environment must be kept separate from all other WebHASE sessions and must incorporate the users data arrays for the simulation.
The servlet receives the parameters passed to it through the GET HTTP method, or the contents of the Initiate form (see 5.1.1). This gives information on the HASE instance to create, what files are required, how to execute it and possibly some uploaded User Arrays. Once the input data has been parsed, the servlet must create a new HASE instance. This is created in a unique directory in /tmp/webhase/<Session Id> on the server, where <Session Id> is replaced by a unique string identifying the client session. The file listing all the HASE files to copy, the location of which is passed as a parameter, is read and its contents copied into the HASE instance. Any files the user has uploaded are then copied into the instance directory and the user is redirected to the applet page that, once loaded, will access the Execute servlet.
Unfortunately, restrictions placed on the form by the use of the HTML file tag, mean that the servlet cannot use the provided methods to retrieve the contents of the form. Instead the form has to be parsed explicitly by the servlet. This is a possible source of many bugs: e.g. if the user attempts to upload a binary file. The lack of support for the file upload HTML tag is a major fault within the servlet API[[12]] as it means that a lot of effort must be made to parse the HTTP input stream which should be handled elsewhere.
5.4.2 Execute
The Execute servlet is responsible for actually executing the HASE instance, with any user arrays that might be updated, and returning an XML file generated from the simulation that has been run.
When the Execute servletis first called by the applet, the user has made no changes to the simulation, and the servlet simply executes the simulation as described below. On subsequent calls, the applet submits Data Arrays that the user may have changed within the request. The servlet writes these Data Arrays to files within the HASE instance directory that it has identified through a session variable that is stored as a cookie on the client. The files that the Data Arrays are to be written to are identified within the request.
The servlet then executes the HASE executable in the directory to produce a new trace file representing the output of the simulation before using the simulation files (.edl, .elf and tracefile.trace) to generate an XML document representing the simulation that can be returned to the client.
The generation of the XML document takes place in three stages. Firstly the .edl file is read to build up a set of simulation library elements and then a tree of instances of those elements that are actually present in the simulation is created from the library. At this stage an XML Document Object Model exists and the contents of simulation entities, their parameters, ports and arrays and the connections between them has been built up.
Secondly, the .elf file is read. This consists of the layout information laying out the different elements within the HASE window, such as the location of ports and parameters. By now, the Document Object Model is almost complete and can be viewed by the applet.
Thirdly, the HASE simulation trace file is read and events are added to the model. The XML document can now be sent to the client for parsing.
A number of design decisions were made in generating the XML document. Firstly, the various files were read as text on a line-by-line basis, without any lexers or parsers being used. This decision was made for two reasons, the file formats themselves, and speed. The nature of the .elf file and tracefile is such that each line can be considered in isolation from all the others, as each line is a complete statement within the simulation. This is not true to the same extent within the .edl files, and so caused some minor problems. However, it was decided not to include a parser for the .edl file as doing so would increase the memory footprint of the servlet and unnecessarily slow the response time. This was a major issue as the running of a simulation takes a significant length of time, and the client might time-out if it did not receive data in a given time.
Another design decision was made with regard to the trace file generated by the simulation. The HASE trace file updates all the parameters within a simulation entity at once, even if only one of them has changed. This is needlessly inefficient and makes XML generation slow, and the resulting file large. To solve this problem, the trace file reader keeps a hashtable of the current value of all simulation entity parameters while reading through the trace file and only generates a new simulation event for those parameters that have actually changed. This relatively easy change resulted in a reduction in file size of over 60% and a significant increase in XML generation speed.
5.4.3 Delete
The Delete servlet is the simplest of the servlets. When called it removes the HASE instance from the server to conserve disk space. It also removes the session variables that have been stored as cookies on the client’s browser by the server. This is important for keeping the system efficient and to avoid filling the server disk with pointless data.
One problem that is inherent in these types of system is the way the server handles client failure. The danger is that the server is left with an orphan process. In this case this happens because the client does not call the Delete servlet, leaving the HASE instance on the server, taking up disk space. This problem has been addressed in a number of ways. Firstly, the session variable for a given client remains the same for some time, so if the client fails and the user decides to run the WebHASE system again, his new instance will simply overwrite the old one, with no change in disk usage. Secondly, when a Delete servlet is called, it checks the timestamp on all the various WebHASE instances on the server. If any of them are more than a day old, they are deleted. As it is unlikely that a user will keep a single applet running for this length of time without requesting a new simulation, it is safe to delete any such instances, as they are likely to be orphans from crashed browsers and applets. This mechanism ensures that the server resources are not overly stretched by having multiple old WebHASE instances left on the disk.
6 System Evolution
During the process of user testing of the system, a number of changes were made to the applet, XML document definition and servlets as a result of user input. The changes from the original design, expressed in part in the Requirements Document (Appendix A), are noted here.
6.1 Applet Changes
One of the major bugs found in the initial system was the problem of the applet not exiting cleanly. The user is able to leave the page containing the applet in a variety of ways other than selecting the Exit menu item in the applet, by pressing the back button or choosing a bookmark for example. This caused problems as the applet window was left suspended, having not called the Delete servlet and was obviously an unacceptable situation for the user, as running the system again created a new applet. Using JavaScript to force the applet to close whenever the user left the applet HTML page, forcing the Delete servlet to be executed, solved the problem, though it does require that JavaScript is enabled on the client’s browser. Other problems with applet crashes were solved by the Delete servlet.
Another problem was caused by the variety of systems that clients use to access the system. While the Requirements Specification Document only specified the use of Netscape Navigator as a client system, students in Livingston, using HASE as part of their MSc course, make use of Internet Explorer. Java has been described as “compile once, debug everywhere”, and this was found to be the case. While this system worked well with Netscape, it could cause exceptions and some strange GUI effects with IE. The eventual solution was to provide guidelines to make the system work with some version of IE, and make use of the Java Plugin. The Java Plugin solution is not ideal as it is 5Mb in size (and see 4.1.2 above), and effectively provides yet another platform that must be debugged.
6.2 Initiate Servlet Changes
Originally it was assumed that users of the system would already have some User Arrays available that they wished to use within WebHASE, that they would upload using the HTML form. It quickly became apparent through user test by the author and others that the majority of users were ignoring the opportunity to upload User Arrays, much preferring to go straight to the applet and editing them there. For first time users without experience of HASE, the initial form is slightly intimidating and it was felt that usability would be improved by removing it.
To solve these problems, an additional method was included to access the Initiate servlet, using the GET HTTP method rather than POST. This meant that the various WebHASE options, usually kept in hidden fields within the form, are instead appended to the URL, and the User Arrays ignored. This means that a user clicks on a link to the WebHASE system and immediately goes to the applet, without having to fill in a form. As well as being faster for users, this is easier to administer. Unfortunately, it does require the encoding of parameters so that they can be used without causing problems with the HTTP server. A simple tool to create the correct URL code was written to help system administrators (see Appendix C).
6.3 Execute Servlet Changes
The majority of changes within the Execute servlet related to the conversion of the various HASE files to the XML document used by the applet. As the system does not use a parser, for reasons of speed, more effort had to be expended to keep the XML generator robust. This, combined with the fact that there were relatively few .ELF and .EDL files to work from (as there is only one of each for a given simulation model), meant that the addition of new models sometimes required changes to the interpreter.
6.4 Delete Servlet Changes
Originally, the Delete servlet was simply used to remove its own WebHASE instance. In order to control orphan WebHASE instances caused by client crashes, the servlet was changed to search for other WebHASE instances to delete as well. While this function could be part of the Initiate servlet, thereby handling the case where the Delete servlet is never successfully called, it was felt that the Initiate servlet was doing enough file operations and this function might slow it down. In addition, common sense would dictate that any deletions should take place in the appropriately titled servlet.
7 The Consequences of WebHASE
The WebHASE system has a number of implications for web-based simulation and the accessing of complicated systems over the Internet. This section deals with the effects on HASE, simulation and the integration of batch processing interactive systems with the web in general.
7.1 Impacts on HASE
The WebHASE project highlighted a number of improvements that could be made to the HASE environment, and to the models within it. A number of changes were made to the DLX and other models to help their integration with the WebHASE system and to provide a more pleasing user experience, making the HASE system more accessible to students.
7.1.1 Accessibility
One of the problems of allowing students to use the HASE system has been the large amount of support required for each user, both initially to get the user started, and to deal with the sometimes-fragile nature of the system. As the majority of users have no need to be able to design their own models or use the majority of the features of HASE, there has been a general reluctance to let students use a system that is more of a research rather than a teaching tool in its accessibility.
The WebHASE system addresses these problems in three ways. Firstly, the user needs no local installation of the HASE system, as they would if using the full system. Secondly, the system restricts the level of interaction that the user has with the underlying HASE system. The user is unable to change the HASE model, for example by adding or removing simulation entities, and can only change User Arrays to modify the simulation parameters. Finally, as the system is integrated within the HASE website, online help can easily be provided in the pages from which the system is started. The system can be made available to any number of users without requiring the huge user support required previously. This moves the HASE system from being only a research tool to an extremely useful teaching tool, accessible to all.
7.1.2 Parameter Changing
Within the DLX model, which was used as a test-case for the system, a number of simulation parameters, such as the latency of the different functional units, the maximum number of simulation time steps and the size of the various memories were stored within a .params file. Changes to these parameters were not considered during the design of the system, as they were assumed to remain unchanged. However, during the course of system testing it became apparent that being able to changes these parameters would allow the user to investigate more features of the architecture. After some discussion, the parameters were moved into a pair of user arrays as part of a new Parameters Simulation Entity. The first of these identifies the parameters and gives information on the type of data that is expected from them, the second contains the actual data values.
7.1.3 Error Detection
One of the major sources of errors made by users of the HASE system has been in the use of User Arrays. The HASE system itself has no way of checking that the contents of a given array are correct, or a standard reporting mechanism for simulation errors. It is obviously undesirable to have such error checking take place within the applet or servlets, as they are supposed to be generic. This means that the onus is on the model designer to check that the DLX Instruction Memory, for example, does in fact contain DLX instructions. During the implementation of the WebHASE system, in preparation for an increase in usage of the HASE DLX model, it became clear that error checking had to be included within the model. Changes were made to the model to include instruction checking within a bu, with the errors and their type being reported in conjunction with the new Parameters Entity. It is expected that error checking and error reporting entities will become more common in HASE models in the future, along with the user of entities to control simulation parameters.
7.2 Impacts on Web-based Simulation
The majority of interest in web-based simulation by modellers has been in using the Internet as a distributed environment for performing simulations, using components such as Java Beans. There has been relatively little interest in exporting existing simulation systems onto the web. The majority of research into web-based simulation has been directed at war game simulation, often funded by the US Department of Defense.
Web Based Simulation packages can be broadly broken down into three different categories. Firstly there are those that do not work, for lack of maintenance, interest or use. Secondly there are CGI-script simulations, which typically involve the user inserting values into a form and receiving some sort of graphical representation of the simulation that has been run. These lack in interactivity, which limits the simulation systems that can be successfully integrated. However, for command line simulation systems they provide a simple method of allowing web-based access.
The last type of simulation system makes use of applets, usually in an isolated context. These provide a larger amount of interactivity, allowing a full GUI to the simulation system. However, there are a number of problems.
1. The limitations on applets (see 4.1.1 above) mean that they are not a good platform for writing simulation systems as they cannot read or write local files. This means that they are never going to be the platform of choice for the simulation modeller, though Java as a language is very popular.
2. The simulation is executed on the client machine, within the confines of the web-browser. For computationally expensive models this is not ideal.
3. The GUI and functions external to the model is written from scratch each time. While some collections of applets do share some GUI components, there is no evidence of being able to plug a new model straight into a GUI. Almost all are written from scratch for the model that they interact with.
There are a large number of applet simulations available, from traffic flow [[13]], to train scheduling [[14]] to a waste water treatment plant [[15]]. All of these suffer from being very model specific, the applet being the model. An exception to this, and a pointer to the direction in which web-based simulation is moving, is the SimJava system [[16]]. SimJava is a generic discrete simulation environment written in Java that can easily be exported to the web as applets.
WebHASE appears to address the problems of both approaches. It provides a sufficiently capable back end that a complex simulation system requiring session level scope, separate user directories, complicated output and user modified files can be handled. The applet front end is sufficiently general that other simulation back ends could be used if required, provided that they created XML documents following the WebHASE XML Document Definition Type, available from the WebHASE web pages.
The efficiency gains to be made for simulation modellers are notable. Simulation systems that are similar to the HASE system in design should be able to be integrated into the WebHASE system with minimal effort, simply requiring a new XML generator and the generation of .gif files for the applet. The pre-requisites for such a system are as follows.
· The simulation system uses discrete time steps.
· The simulation model consists of a number of simulation entities containing simulation functions, connected together by streams along which messages can pass. Simulation entities contain state, which can be indicated graphically or using text. Streams cannot have state.
· A simulation run is represented as a transformation of a number of user files into an output files that can be subsequently interpreted, possibly by a graphical tool.
· A simulation run can be executed from a simple command line, without requiring the use of a graphical user interface.
· No user interaction is required during the simulation run.
· The simulation output file can be interpreted as being a number of events, each of which affects the state of simulation entities, or a messages passing along a stream.
If these prerequisites cannot be met by the simulation system, it may still be possible to make use of the WebHASE applet provided that a back end system can be written that generates an XML document that is correct according to the WebHASE XML Document Definition Type.
7.3 Implications for Using Complicated Systems over the Internet
When Java was first developed a great deal of hype surrounded the creation of applets. However, people soon became tired of waiting long times for an applet to download so they could watch a ball bounce within a box, along with slow interactivity. As time went on, applets fell by the Java and internet wayside, to be replaced by other plug ins and server side technologies instead of client side.
However, there are limitations in using only server side technology to provide an interactive system with a web front end, namely the limitations of HTML, JavaScript and request/reply nature of browser based interaction. At the same time the size and complexity of systems integrated with the web has increased along with internet speeds. Internet applications are still limited to those that involve a simple request/reply interaction model.
Java applets have made some progress in providing interactivity over the internet, including the IBM HTTP Server Administration Tool and internet games. The limitations of form based server side applications will be reached rapidly, and the next generation of Internet applications will require the extra interactivity provided by Java applets. At the same time the use of Java servlets, with their huge developer base, class libraries and industry support will dominate the back end of the internet.
The WebHASE project has demonstrated the speed at which a fully functioning Internet application requiring a high degree of interactivity and interactions with a complicated back end can be developed. The technologies used in the project are all well established now, with a large developer based available, and are designed to integrate well together.
8 Further Work
As with any project of this nature, there are more improvements that can be made to the system as well as being new areas of the knowledge map to be explored. Some of the directions in which this work has pointed are described here as seeds for future projects.
The WebHASE XML format, though probably sufficiently general for most simulation systems, is not a standard. The generalisation of the WebHASE applet to allow its use in other discrete simulation systems, probably by attempting to integrate it with another, quite different system would be an interesting challenge.
The WebHASE XML format was designed to mimic the internal data structure used to hold the simulation within the system. A process of trial and error achieved the speed of writing and reading the XML. As XML is fast becoming the data standard of choice, research into finding the fastest and most efficient way of storing information for future retrieval by a different system could be useful.
The textual XML format is quite verbose. Compression algorithms designed to compress entire tags as opposed to simply the text of the XML would likely to have an impact on the greater XML community.
At present the WebHASE applet only allows the user to change a small number of parameters within the system, it does not allow the user to design simulation models. If the system could be expanded to allow its use as a tool for designing models, the Holy Grail of a fully web-based simulation system would be reached. This is quite possibly a much greater challenge than building the system in the first place, as it would involve work in giving users a virtual workspace on the server and allowing a much higher level of interactivity.
It would be useful for users of the demonstration system to be able to select from a number of different simulations from within the applet, allowing the user to see pregenerated simulations, showing different aspects of the simulation model or with different simulation parameters. The XML DTD already supports this, so the only changes necessary would be the addition of some dynamic menu items based on the XML document that is read in, and the ability to read a new simulation into the applet, something that is already supported within the full system.
The current support by the Java servlet API for the HTML file input tag is unacceptable. While the handling of different file formats by HTTP and servlets is a challenge, especially given that the user can return any file they choose, a small package of utilities to make the job easier would be most beneficial.
9 Conclusion
The WebHASE system can be considered a success. The system is now running happily within the Division of Informatics at the University of Edinburgh, and is being integrated into the ILSE. The project itself has been fortunate in that there have been fewer problems than one might expect. As with all these projects, in part this is due to finding the correct path to follow early on, but in part it is due to the general high standard of the Java technologies used, and the ease with which they can be integrated with XML and each other.
The project has shown that it is possible to integrate a non-trivial system, which cannot simply be accessed via CGI scripts, with the internet to provide a robust environment for remote computation, in this case simulation in the HASE environment. As such, it points towards future web applications using a combination of client and server side computation with XML as the interface between them. As the internet moves from a document model (where the main resource is HTML) to an object model (where the resources are objects, some of which may be documents) [[17]], these sort of web-applications will become more common. We can expect to see a revival of interest in Java applets, but as part of a distributed system rather than only as standalone applications.