Robust MPI Message Delivery with Guaranteed Resources
Greg Burns, Raja Daoud
Ohio Supercomputer Center
Columbus, Ohio
Introduction
A mechanism for message delivery is at the core of any
implementation of Message-Passing Interface
(MPI) [1].
In a distributed memory computer, shared or not, it is
most feasible to synchronize messages in the local memory
of the destination process. Accordingly, the initial
step in message delivery is for the source process to
transmit a message envelope - a small packet containing
synchronization variables and possibly other information
(p. 19) - to the destination. Whether or not an MPI
implementation provides buffer space (p. 27, ll. 26-32)
(buffer space is for the message data, the application's
data), it must store envelopes in the destination local
memory when there is no matching posted receive. As
local memory is a limited resource, so too is message
envelope space.
MPI recognizes that any pending communication consumes
resources and that overflowing resources may
cause a communication routine to fail (p. 32, ll. 14-15).
By using source rank, tag and context, a process can receive
messages in an order other than the arrival order
and thereby force envelopes to accumulate in the local
queue. The more disorderly the receive sequence, the
higher is the program's dependence on the envelope
queue.

Synchronize at Destination - It is most feasible
to synchronize messages in the local memory of the destination process.
This paper examines alternatives for guarding the envelope queue,
detecting overflow conditions and reporting
them. It addresses the interpretation of MPI's guarantee
on message progress (pp. 31-32, ll. 28-3) as a constraint
on envelope queue management. Finally, a portability
tactic is suggested for implementations, applications and
libraries as a solution to conflicts over limited resources.
Out-of-Order Message Receive
Without global synchronization at the application level,
the order of message arrival from all source processes is
a matter of concurrency and timing. Heavier traffic from
one source may eventually consume the entire envelope
queue, at which point a receive operation from another
source will cause an overflow. Should a message delivery
system impose global flow control? While it can be
argued from a hardware perspective that global flow
control is the responsibility of a robust parallel application,
MPI is defined within a process model (i.e. not a
hardware model) and MPI advice on "safe" application
design (p. 27, ll. 38-46, pp. 33-34, ll. 44--8) does not include
global flow control.
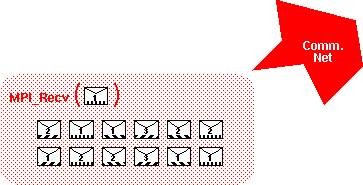
Disorderly Receive - An application can use source
rank, context and tag to filter incoming messages. Arriving messages
that do not synchronize must be stored.
Tag and context synchronization filter the stream of messages
arriving from one source. Here the disorder is created
explicitly in the sequential programming of two processes.
When the disorder is greater than the available
envelope queue, an overflow results. MPI cautions
against such "unsafe" programming with regard to message data,
but neglects to state that the problem is identical with
message envelopes. Consider that zero length
messages do not make an unsafe program safe.
Implementation Strategies
An MPI implementation must decide whether or not to
impose global flow control by reserving envelope space
for each source process and, at a minimum, implementing a
virtual circuit protocol between the destination and
each source process to guard each source's envelope
queue. The trade-off is between the simplicity and user
friendliness of a guaranteed pipeline between every process-pair
and the inherent non-scalability of the supporting protocol.
Implementations that heed MPI's advice on
safe program design may feel compelled to guarantee
that a safe program never fails due to resource limitations.
Yet the standard does not mandate this behaviour.
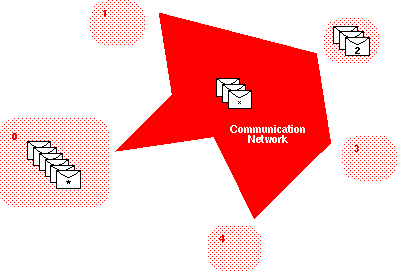
Simple Store and Forward Network - The most
efficient and scalable solution could allow one source process
to swamp the envelope queue.
Without global flow control, only the destination process
will detect an envelope queue overflow.
By detecting overflow only at the destination process,
the application is kept alive until the last possible moment.
However, the source process(es) may continue
past the send operation that overflows the envelope
queue. If that send operation, or any subsequently posted
send operation would actually satisfy the overflowing receive
operation, a user may claim that the application
failed to complete a matching and posted send/receive
pair, thus violating the MPI guarantee of progress.
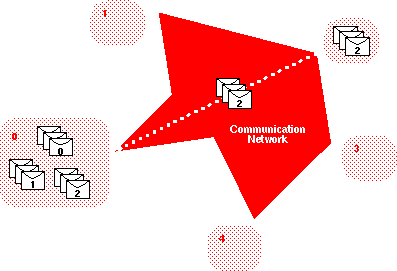
Global Flow Control with Virtual Circuit - Detect
envelope queue overflow only at destination, but users are confused
about the progress guarantee.
The implementation may report an error to the destination
process or it may simply leave it in a deadlock state.
By deadlocking, the application never exits due to envelope
overflow. With no report of resource overflow, users may
strengthen their claim that the implementation
could violate the progress guarantee. Contrary to the advice
in the document (p. 34, ll. 6-8), a deadlocked application
may be easier to debug than one that has exited because
the synchronization state of the processes and the
stored message envelopes can be examined.
Source Side Detection
With global flow control, envelope queue overflow can
also be detected at the source process, provided an end-to-end
protocol is used. The implementation blocks a
standard send that consumes the last available envelope
and errors a non-blocking standard send that would consume
the last available envelope.

Global End-to-End Flow Control - Overflow can
be detected at the source. The most robust solution has poor
scalability.
This is a conservative detection and reporting approach.
When the source process is aware of only one available
envelope at the destination, it cannot know whether or
not the next receive operation by the destination process
will consume an envelope in the queue and free its space.
The answer may be in the future execution of the destination
process or even in an acknowledgment message
that has not yet reached the source process. The implementation
has to assume that a buffer overflow is possible.
For standard send, it blocks the operation. If the receiver
is simply slow, this will only cause a delay. A non-blocking
standard send must cause an error.
The advantage of this approach is improved debugging
and greater respect for the progress guarantee. Users
never detect a circumstance which appears to violate the
progress guarantee. The disadvantage is the scalability of
the end-to-end protocol.
Source side detection can cause mysterious behaviour of
buffered send. The MPI standard teaches that by providing
buffers in user space, an application can guarantee
that messages will be buffered up to a known limit (p. 28,
ll. 1-8). The implication is that a buffered send is guaranteed
to complete. With source side detection, an envelope queue
overflow must fail a buffered send because it
must not be blocked. This occurs in spite of the fact that
ample space may be remaining in the attached buffer.
Observations on the Progress Guarantee
Although not as precise at it could be, the MPI statement
on resource limitations clearly takes precedence over the
guarantee on progress. Global flow control, overflow detection
and overflow reporting are quality of implementation and
performance issues. It is not obvious which
strategy has the best quality. Even an implementation
that does not offer global process flow control is valid
and is not by design violating the progress guarantee. In
short, the progress guarantee forces nothing beyond
common sense upon implementors and is not a clause of
refuge for users that stress envelope resources.
The progress guarantee would be a serious constraint on
MPI message delivery if message envelopes were not
considered a limited resource whose overflow could
cause a communication to fail. If the MPI standard were
interpreted in this way, overflow detection at the source
process would be mandatory. End-to-end protocol would
be mandatory. It would be forbidden to allow a send to
be posted whose envelope could get stuck in the communication
network or the source process - places where it
would not synchronize. The only alternative would be
for destination processes to search for synchronizing envelopes
in remote memories. None of these choices appear to allow
for scalability with high performance.
The MPI progress guarantee is odd because it is only tolerable
when rendered moot by another guaranteed property of message
delivery - resource (envelope) limitation
errors. Previous message-passing systems have found it
better to say nothing on either point.
Portability with Limited Resources
Are limited envelope resources only a problem for
pathological applications? Given the range of memory
resources in machines that might take advantage of the
MPI standard, "common practice" applications (p. 34, ll.
3-5) may provoke envelope queue overflow. Consider an
application with the following synchronization points
and runtime configuration:
- 128 total processes
- 4 processes per node
- 4 communicators
- 8 tags
- 1024 byte short message size
The number of processes per node is important because
they all share one limited local memory. The total number
of communicators is the sum of those created in the
main application and those created by any libraries.
With only two tags and one communicator, an application has
the means to force an arbitrary number of envelopes to be
stored (by sending multiple copies of the first
tag to a process blocked on the second tag). For a more
realistic demonstration, assume that on each communicator
eight messages with eight different tags can arrive
in any order, but all will arrive before a second set of
eight messages is sent. If no order is imposed on the four
communicators, the maximum per-source envelope storage
count is 4 x 8 = 32. With 128 possible sources, each
process's maximum storage count is 32 x 128 = 4096.
Most distributed memory MPI implementations will be
compelled, for performance reasons, to aggressively
send short messages with the envelope. Thus wherever
space for an envelope is required, space for the maximum
short message size is also required. Assuming a
1024 byte short message maximum size and neglecting
the much smaller envelope size, each process's maximum
envelope+buffer storage size is at least 4096 x
1024 = 4 megabytes. Since up to four processes may be
running on the same node, each node's maximum envelope+buffer
storage size is 4 x 4 = 16 megabytes. This final number
would take a large bite out of available data
storage on many different parallel machines.
An application with the above parameters may in fact not
receive messages out of order and may only require the
minimum amount of envelope+buffer storage (1 envelope+buffer
~= 1024 bytes). The demonstration numbers
can be adjusted, some reduced and some increased, but
the example is not extreme and the potential envelope+buffer
buffer storage requirement is frightening.
Since "common practice" applications can approach and
exceed an implementation's limited resources, a portability
question arises. A practical solution is to advertise a
Guaranteed Envelope Resources (GER) figure for resource
limitation and usage.
Guaranteed Envelope Resources
The envelope queue size is most easily understood on a
process-pair basis which requires global flow control in
the implementation. To keep things simple, GER is defined
as the minimum limitation or maximum utilization
of a guarded envelope queue for any process-pair. An
implementation advertises its GER and guarantees that
applications which do not exceed the GER will not fail
due to envelope resource overflow. Implementations
choose a supportable GER given the total number of processes
and number of processes per node that they allow.
If memory is shared with other software, MPI implementations
should not permit an application to start if the advertised
GER cannot be guaranteed due to a (temporary)
memory shortage. In these circumstance, a user could be
allowed to contract for a lower but still sufficient GER.
Off-the-shelf applications and libraries must also advertise
their GER. Matching MPI applications with implementations
becomes like matching PC applications with
computers. Computers clearly advertise their disk and
memory sizes and applications clearly advertise, on the
side of the box, their disk and memory requirements.
Estimating GER
Programmers calculate a GER when building an application
or library. A minimum GER of one allows an envelope
to be read from a communication network, stored
and examined. A maximum envelope queue size is estimated
for each communicator that includes both sides of
a process-pair. The results from all communicators are
summed, giving a maximum for a process-pair. The
maximum of all these pairs becomes the single GER.
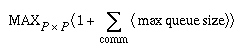
Estimation of the maximum queue size for each communicator
is done in one of two ways, depending on send
modes and blocking semantics:
- When standard sends are used exclusively, the maximum
queue size is the maximum receive disorder
created by using the message tag. Another explanation
is the "unsafe" message count, from the description
in the standard (pp. 33-34, ll. 44-8).
- Whenever non-blocking sends are in the mix, the
maximum queue size is the maximum number of
unreceived messages generated by any send routine.
This is because throttling the source process through
blocking is not an option and some conservative implementations
(see Source Side Detection) may
have to error the non-blocking send. Flow control in
the application is implied or else the maximum
queue size is unbounded.
Synchronous and ready sends do not stress the envelope
queue because synchronous mode has inherent end-to-end
flow control and ready mode requires that the consumed
envelope will be immediately released by a pending receive.
It is certainly possible to further optimize these estimates.
However, optimization must be tempered with
clarity and simplicity for users. The main objective is to
shine a light on a plausible impediment to application
portability.
Conclusion
The progress guarantee introduced by MPI does not, by
itself, change the message delivery issues fundamental to
all previous message-passing systems, because these issues
are dictated by the realities of hardware and machine
architecture, not by software semantics. Instead,
the GER figure of merit assists the user in evaluating the
robustness of message delivery systems and the portability
of applications.
References
- Message-Passing Interface Forum,
"MPI: A Message-Passing Interface Standard", Version 1.1, June 1995
This paper was presented at the
MPI Developers Conference,
June 22-23, 1995 at the University of Notre Dame.