



Next: Stage 1: Repartitioning
Up: Temporal Join Processing Model
Previous: Preliminaries
In the previous section, we gave a rough outline of how a temporal join
is going to be processed on the architectural model. Here, we give a
precise, stepwise description of this process. It is based on the
symmetric partitioning that was discussed in
section 3.5.2. Thus the process comprises the
following three stages (see figure 3.19):
- 1.
- A (re-)partitioning stage in which fragment are repartitioned to create fragments . The same is done for the . See
figure 8.9.
- 2.
- A joining stage in which the RQk are computed for
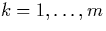 . See figure 8.10.
. See figure 8.10.
- 3.
- A merging stage in which the partial results are merged
and written to disk.
In the remainder we will concentrate on the stages 1 and 2. Stage 3
might be omitted if further processing requires the data to be
partitioned. Furthermore, from the performances comparison's point of
view, one can argue that the time spent on stage 3 is (more or less)
the same for all cases as it only consists of writing the join result
(which is the same in all cases) to disk. It would only increase an
already existing difference if some computations have already been off
balance and have caused big partial results. But such an
`off-balance-situation' would already be penalised by a poor
performance in stage 2, the stage that creates the
`off-balance-sized-results'. Therefore, stage 3 would only contribute
marginal differences in the overall performance. Consequently, we can
concentrate on the costs of stages 1 and 2 in order to create a
performance model that allows us to compare computations using
different partitions. In the remainder, we look at the processing
within these two stages.
Next: Stage 1: Repartitioning
Up: Temporal Join Processing Model
Previous: Preliminaries
Thomas Zurek