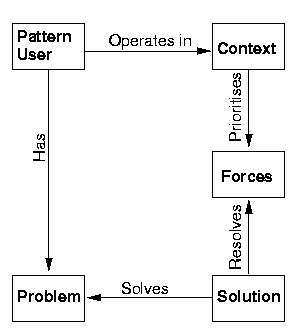
Figure 1 - Relationships Between Pattern Elements, from Meszaros
& Doble [5]
To Do
The virtues of patterns are that they document best practices and lessons learned. Figure 1 shows how the user of a pattern has a problem within some context. There are forces which pull the user (for instance cost, time and quality) and some of these may pull in opposite directions or be mutually exclusive - "you can have it good, quick or cheap; pick any two", anon. The solution proposed in the pattern will solve the problem in a way which resolves the most important forces which the context has prioritised. Patterns also help provide a shared language that practitioners can use to communicate in short hand. This can be achieved by giving the pattern a short, evocative name; ensuring the name can fit well into discussions; and having the name reflect either the action or the structure proposed in the solution.
The format of the patterns varies considerably, but the template chosen for this paper is to have a context section which includes a discussion of the forces and how they interact, a problem statement, followed by a solution and a consequences section which describes the resulting context and how well the forces have been resolved. Some of the patterns in this paper also include related patterns and known uses sections. In general, patterns are validated by having been seen to be successful a number of times - usually three times as a minimum (the Rule of Three [26]).
Figure 1 - Relationships Between Pattern Elements, from Meszaros
& Doble [5]
When patterns are collected together and meaningful links are provided between them, they form a pattern language. Such links can point the reader to patterns that would naturally tend to come before or after the current pattern. They can also provide alternative, related or supporting patterns. Ideally, a pattern language should provide synergy and wholeness by allowing successful solutions to work together.
The literature on reengineering legacy systems proposes a number of useful solutions to reengineering problems. However, the nature of some of the standard research literature - with unintentionally ambiguous abstracts, inconsistent formats and definitions, the necessity to provide lengthy details of specific project context and the repetition of salient background - can make it difficult to readily access this expertise. Readers may have to expend considerable effort in trying to establish the authors' key messages. Having expended that effort, they may find the contents of the paper do not help them. For this reason, this paper proposes the use of patterns to provide a convenient, powerful and consistent view of the experiences contained in reengineering literature. In addition, by abstracting away from the specifics of an individual project, the opportunity arises to see the same solution apply to the same problem, within the same context. If the right abstraction can be achieved the process described in the pattern attains some validity as a successful reengineering solution and greater applicability by virtue of being generic.
We have concentrated on reviewing the literature that provides salient case study material. This strategy allows the resulting patterns to draw upon more tangible evidence than if we had included more propositional or theoretical work. Inevitably, such filtering of the literature further clarifies the state of good practice from the large number of works in reengineering.
This paper attempts to re-expresses published reengineering experiences into a patterns format in two ways. We start by taking case studies from literature and presented them in a pattern style. We would not claim that these reformatted case reports were conventional patterns due to their lack of known uses and their lack of focus on specific issues. We shall call these Case Patterns. Subsequently, however, we identify other, more conventional, patterns that we have seen recur in the literature. The objective of the paper is two-fold: to encourage others to adopt the pattern as a template for recording their experiences; and to make successful solutions more accessible to the reengineering community. We also hope to elicit feedback which confirms that others have seen further instances of the patterns. This will lend greater validity to the patterns. We also encourage feedback on levels of abstraction- by obtaining the correct level of abstraction, the patterns will be more useful to more people.
The value of these case patterns lies in them providing a consistent and powerful template to record experiences. Indeed, Tilley and Smith [6] suggest that a template for cataloguing case studies would be a useful way of sharing experiences. The power of the pattern format comes from encouraging authors to consider the forces that acted upon the project context and how the execution of the project resolved (or otherwise) these forces. By making forces explicit, and not demoting them to asides in the introductory preamble, users of case patterns can readily assess the applicability of the solution to their own situation. Furthermore, notice how the case patterns are not merely summaries of the case studies. Instead they draw on the lessons that were learned and show how the solution that was, or might have been adopted in retrospect, has advantages and disadvantages.
The pattern titles are invention and are intended to help communication by providing an evocative name that captures the essence of the solution, or the structure produced by the solution. More comprehensive summaries of the papers are provided in the Appendix to show the foundation of the patterns.
This first case pattern is abstracted from a case study provided by Adolph [7] who was involved in reengineering a rail-scheduling legacy (see Appendix). His concerns, about making estimates based on productivity gains expected by adopting tool support, echo Sneed's [27] sentiments from more than a decade earlier.
| Case 1 | Museum Manager from Adolph [7]. |
| Context | A legacy system exists which has worked successfully for many years.
It is written in an archaic language (which makes technical people difficult
to recruit) and limited system memory makes it incapable of dealing with
future demand. The system is to be migrated to a more modern hardware
and software platform and certain new features, agreed with the customer,
have to be added. There are project budgets and timescales to be adhered
to. The project team are predominantly unfamiliar with the legacy and,
because of its archaic language, are reluctant to read its code. Programmers
want to add their own new features and redesign inelegant algorithms.
By adding new features and redesigning inelegant features, customer satisfaction may be increased, but the project's budgets and timescales will be stretched. If the programmers largely ignore the source code and concentrate on the customer's specification they may start coding earlier, however they will probably miss valuable domain knowledge. By redesigning inelegant features they may improve future maintainability or system response, but potentially throw away many years operating experience contained in the legacy code. Tools are important to the productivity of the team, but tools can add an administration burden and novice users may not be able to attain expected productivity gains. |
| Problem | How can the archaic legacy code be migrated to a modern format? |
| Solution | Get the team to respect the legacy and understand their tools. First, understand the legacy: ensure that all staff read the code and available documentation by making this part of the job performance review; and hold workshops to educate the staff in the history of the legacy and the domain. Adopt a phased migration strategy, using the small, early phases to test and become familiar the tools and methodologies used. Train staff in the use of the tools and make schedule estimates based on the level of expertise that the team has in using such tools. Only allow new features (outside those in the customer's specification) and redesigns of old features to be incorporated if they directly reduce the project's costs. Dedicate one member of the team to be a toolsmith. |
| Consequences | If the team understand the legacy and the domain, they are less
likely to miss important system features, dependencies and exceptions.
However, this effort may have an associated time penalty. Making understanding
the legacy part of a performance review encourages staff to comply.
Adding new features beyond the agreed specification and re-implementing features that programmers find inelegant, may introduce extra risk to the project. If the programmer is forced to justify any such change to the specification in terms of benefits to the project, the risks can be reduced. In addition, by using more of the original legacy, fewer test procedures will have to be re-written. Training the team in the use of the tools will add cost and delay to the project. However, they will gain some familiarity with the tools - although they are unlikely to become experts unless they have had some live experience on previous projects. Small phases at the beginning of the project allow the team to become more familiar with the tools and allow the effort required for subsequent phases to be more accurately estimated. If the initial estimates are drastically wrong, the customer will perceive failure when revisions are made. Therefore, it is essential to base the estimates on the level of experience of staff, instead of the claims the tool's vendor makes for productivity gains. If there is a dedicated toolsmith, the administration burden associated with the tool will not have to erode the effort of a valuable programmer (Brooks [8] pointed out the importance of a toolsmith as far back as 1975), however an extra team member with no direct impact on the artefact being reengineered may be difficult to justify within your budget. |
The next case pattern is derived from DeLine et al. [9] who deal with reengineering a CASE tool from batch to interactive operation - more details in the Appendix.
| Case 2 | Reengineer for Interaction (need better name!) from DeLine et al. [9]. |
| Context | A legacy system currently runs in a batch mode. It is now to operate
interactively, have its interface improved, and provide the ability to
work on multiple instances of the work product (an example of a work product
would be a document in a word processor).
Functionality in the batch program is probably tightly coupled, but the interactive system needs to have cleanly decoupled stages. The order of operation in the batch system is predetermined, but interactive processing is user defined and inputs can be incomplete. The interactive system can work on multiple products and may persist for a long time, neither of which are probably true for the batch implementation. Memory management may not have been a concern for the designers of the batch system, but an interactive system needs to continually create and delete data. If there is an error in the inputs to the batch system, it will simply abort. However, the user of the interactive equivalent would be inconvenienced if this happened. |
| Problem | How should the migration from batch to interactive operation proceed? |
| Solution | Build a UI, extract the logic and design a data model to support tolerant, persistent editing of multiple work products. First, choose a suitable architecture - either state driven (the interface and logic access the data as and when they need it. ) or event driven (the interface and logic are informed, and take any necessary actions, when the data changes). Use an internal shared data model or an external shared data repository. Design a suitable UI for the interactive system, extracting functionality from the legacy to support the UI and providing services to edit the work product. Build in error tolerance and reporting. Reengineer the data structure to allow multiple work products to coexist. Budget and manage memory throughout the process. |
| Consequences | The choice of architecture is important. A state driven solution with
an internal data structure provides a fast response time and is useful
if their UI and application logic are to be closely coupled. An external
data repository would suit if the two components are already loosely coupled
or you wish to decouple them, but will provide a slower system response.
Event driven solutions provide a loose coupling between the UI and application
logic. Alternatively, the data could be encapsulated in an object which
informs both components when changes occur to data items. The encapsulation
also insulates the data and logic from changes to the UI.
The design of the UI should guide which items of functionality need to be excised from the batch implementation. However, since you are adding editing functions, there is a danger that data dependencies between functions create unforeseen behaviour. Also, since the inputs are now user driven and are therefore no longer in a prescribed order, the system must be tolerant of incomplete inputs. Be prepared to devote a great deal of effort into developing the UI. Moore [10] reports that most of the code of interactive systems can be devoted to the UI, whereas there may be none or very little in its batch predecessor. Having providing tolerance of errors in the inputs, the interactive system should recover gracefully instead of terminating. However, more meaningful and constructive feedback needs to be provided to the user than was present in the batch system. The data structure can now handle multiple instances of the work product. In this way, a delete operation, say, should be able to distinguish between the same types of data items in distinct work products. Furthermore, by managing memory the system should be able to reclaim memory from deleted data items and reclaim that storage for subsequent data creations. |
Duncan and Lele [11] have recorded their experiences of migrating a mainframe system to a client/server implementation incorporating Commercial Off-The-Shelf (COTS) applications. Again, a more verbose summary of the paper is given in the Appendix.
| Case 3 | Buy & Build (aka Customise COTS) from Duncan & Lele [11]. |
| Context | The mainframe legacy handles almost all of the business processes,
but the code is undocumented, maintenance is expensive and the database
has evolved with the business - not with standards. A migration to client/server
architecture is planned which should gain the company competitive advantage,
give more flexibility and reliability, allow growth and provide greater
system integration. You wish to move to standard off the shelf products,
since writing applications from scratch would be too expensive and would
take too long, but none exactly fit all the requirements without considerable
customisation. In addition, you are concerned about quality system accreditation,
user and developer training and general resistance to change.
Whilst reducing running costs is important, it is secondary to achieving business objectives. However, the migration project must remain within budgetary and time constraints. A new system could be built from scratch and would meet all functional requirements. Nevertheless, bolting together commercial products could realise cost savings, yet it would require customisation effort and introduces the risks associated with having to manage vendors. Although buying off the shelf products prevents you from re-inventing a number of wheels, you will have to invest in understanding these products and their interoperability and will still be left with untried customisations. If the vendor ceases to trade, you may be left with an unsupported application - not the case if you develop it yourself. Having to conform to the standard interfaces supplied with third party products may increase user training and resistance to change. Quality assurance documentation will also have to conform to the new workflow processes prescribed by these products. |
| Problem | How can the legacy system be migrated to commercial off the shelf applications? |
| Solution | Involve external and internal experts in the phased migration to the new products. First, install a suitable client/server architecture and appropriate commercial software products - including a RDBMS which can interoperate with the other products. Hire a respected consultant with relevant expertise, as well as sufficient resources, to customise the packages and maintain the evolving system during the project. From internal staff, appoint a data administrator and second people from all stakeholder functions to work on the project team. Document current processes and the evolving system. Build redundancy and fault tolerance into the network. Migrate incrementally, each phase dealing with one business function, and deliver reengineered modules as quickly as possible. Make user training part of each phase. As necessary, get vendors together to resolve problems. Gradually hand over system maintenance to in-house development staff. Reward people at their annual reviews for their commitment to the project. |
| Consequences | Having bought commercial supported technology - instead of developing
your own - you rely on tried an trusted technology, share some risks with
the vendor and can rely on the vendor's expertise. However, you still have
to understand these products, but you have used an experienced consultant
to help fill the gaps in your understanding and can take the opportunity
to learn throughout the project. This you achieve by gradually handing
over maintenance from the consultant to your own people. Nevertheless,
you are still faced with a major problem if a product becomes unsupported.
The involvement of internal staff helps secure their commitment to the project, ensures their domain expertise is incorporated, helps document existing procedures and enables them to learn about the new system - which enables them to assist in training other staff. Since you are building up your documentation throughout the project, you may be able to re-use this for quality assurance accreditation since it should reflect your systems and procedures. The project is phased. Therefore, you are left with a stable, working system at the end of each incremental migration. If errors are introduced, or requirements change, it is relatively easy to fix/ammend each small artefact. Since there are a number of vendors involved in the project, there may be a tendency for them to blame each other when things go wrong. By having meetings where all parties are represented, the guilty can be shamed into action. Also, problems can be resolved more quickly than if you, the customer, were a remote mediator in a dispute. Although one migration phase may involve more than one commercial software product, the phase has been functionally orientated and should only involve one sub-set of users. This will focus training and minimise uncertainty since subsequent phases should not severely impact those users. If the delivery of new modules is achieved quickly, there is less likelihood that the organisation will have time to think up new requirements with which to delay and confuse the reengineering effort. Resistance to change has been reduced by the involvement of users in the project team, by including training in the programme and by rewarding staff contributions during annual reviews. |
This next pattern combines two similar case studies (Hughes et al. [12] and Sneed and Majnar [13] - see Appendix) which deal with the use of Object Request Brokers (ORBs). Notice how these authors, unlike the others we have reviewed, do not highlight the importance of people in the reengineering process.
| Case 4/5 | Wrapped Service from Hughes et al. [12] and Sneed and Majnar [13]. |
| Context | There are a number of legacy applications which each rely on their
own implementations of the same functionality. For example, various military
systems need to display maps. These implementations may be written in different
languages, have varying levels of sophistication and their hosts may be
geographically dispersed. Each instance of this functionality requires
maintenance. There may even be commercially available products that can
supply the functionality.
Having one instance of the service would reduce maintenance costs, but the change would have associated risks and costs. By moving to this single instance, there is an opportunity to provide standard system interfaces and so take advantage of standard commercial applications. However, standardisation may loose some of the useful idiosyncrasies of particular implementations of the service. |
| Problem | How can duplicated functionality be made into a common service? |
| Solution | Wrap the functionality to provide a common interface to a common service for all the applications to use. First, consider the costs and benefits of providing some functionality as a common service - taking account of current and future maintenance costs, as well as the costs of the migration. Prioritise the applications which will be affected, by the benefits that can be achieved. Choose configuration tools to help manage version control. Extract and reengineer the functionality from one of the applications and provide it with an interface in the form of an object wrapper. Reengineer each application in turn to use the common service by invoking a distributed ORB, such as those complient with the CORBA standard. Remove the now redundant functionality from the application. Now test and deploy, before moving onto the next application in the list of priorities. |
| Consequences | By considering the costs and benefits of providing a common service,
the project is properly justified. As such, the project has a greater chance
of being successful and being supported through to completion. The risks
to the project are further reduced by working on one application at a time.
If the project ceases you are left with stable working systems and will
have tackled the most important areas first.
Eventually only one instance of the service is left which will reduce maintenance costs and reliance on the legacies. However, if this service goes down - for whatever reason - all of the applications will be adversely affected. Since the applications rely on a standard ORB interface, the opportunity exists to replace the service with a commercial product which can provide the same interface. Bear in mind, however, that the standard may become less popular in the future and be replaced by a new generation of interfaces. Inevitably, the wrapped code will need to be changed to interface with the wrapper. Indeed, the code may not be readily decomposable from the legacy. Whatever the case, such adjustments provide an opportunity to make the code easier to maintain (Fanta and Rajlich [16] claim that even small restructuring steps can have a positive effect on the code's comprehensibility and maintainability). However, to retain the idiosyncrasies present in the original applications may prove too costly and some compromises may have to be reached. To make the legacy applications easier to understand and maintain, the now redundant functionality should be removed, but time and cost constraints may not allow this. There are multiple applications being worked on; perhaps at different times, in different places and by different people. The proliferation and tracking of the effects of even a simple change can become complex. Configuration management tools help manage the different and changing versions of the various applications involved in the project. It is time consuming to test distributed systems, however testing will contribute to the success of the project. |
There are already some patterns which provide solutions to problems in the design of new User Interfaces (UIs) [14]. However, Plaisant et al. [15] report on a high-level, low-effort strategy for reengineering existing UIs.
| Case 6 | Low-Effort User Interface Reengineering from Plaisant et al. [15]. |
| Context | The current User Interface (UI) of a legacy is unsatisfactory and there
is a need to improve user performance and user satisfaction. The underlying
legacy functionality is satisfactory and there are limited resources available
for reengineering. You are concerned about disrupting users if changes
to the UI go ahead.
Whilst an improvement in the UI might make user perform better, they may be resistant to change. They will also resent any disruption the reengineering causes them and will be intolerant of having change imposed on them. Since resources are limited, you need to manage the extent of reengineering and any resulting training costs. Reengineering itself will have associated costs which also have to be managed. |
| Problem | How can the UI be improved with minimal effort? |
| Solution | Understand the system and users in
order to prioritise incremental action. Learn as much as you
can about the system by reviewing documentation, attending training sessions,
interviewing personnel (managers, developers and users), observing users,
using the system yourself and administering questionnaires. Identify problems
areas, estimate the effort required to fix the problems and rank your recommendations
for change in terms of the benefits that can be achieved.
Problems with: system access can be rectified by making equipment more available and streamlining login procedures; data display can be improved by using highlighting, field ordering, mixing upper and lower case and removing redundancy and obscurity; data entry can be tackled using defaults, removing redundancy, touch screens, limited cursor movement and consistent key sequences; consistency in general will be improved by having common action sequences, terms, units and formats; and finally by having a positive tone, providing useful guidance, avoiding redundant information and having a consistent format, error and system messages can be improved. Reengineer the interface in a number of phases to address the necessary changes. As appropriate, include periods of stability where the users will not experience change until they have had time to adapt. |
| Consequences | Being familiar with the documentation, you may decide that on-line
help, FAQs and better user manuals may provide an opportunity to improve
the system's usability. Interviews with managers elicit goals and available
resources. Interviews with developers elicit system constraints and alternatives.
Interviews with users elicit frustrations and expectations. Observing users
highlights how routine tasks are carried out, what bottlenecks exist and
may show differences between experts and novices. Expert review (using
the system yourself) gives you another view on the issues and difficulties
involved. Questionnaires are useful to reach a large numbers of users and,
if administered after reengineering, can be used to measure the benefits
of the changes.
Having understood the system and spoken to the interested parties, you will have built up relationships and credibility. As a result, you are less likely to be seen as imposing unnecessary change. However, time spent with users will probably highlight additional functionality which they desire. Incorporating such changes to the specification runs the risk of increasing project time, cost and risk. It also dilutes the effectiveness of the intended reengineering. On the other hand, ignoring requests for new features could jeopardise the project's credibility and lead to user/developer/manager dissatisfaction. It could be argued that reengineering in phases only prolongs the disruption caused to users, but this must be tempered with the practical cost and resourcing issues that constrain the project. A gradual evolution of the UI with suitable stable periods will also reduce the impact on users' training requirements as they can assimilate the small changes during the course of their own work. Your credibility, and so user acceptance, will also benefit from the phased approach since any bugs can be more easily identified and fixed. In addition, the latest release serves as a prototype- if you have missed some fundamental requirement it can be identified and incorporated into the next iteration. Ranking problems and reengineering in phases means that limited resources can be targeted at the areas which have the greatest benefits. The resulting UI should aid faster learning and improve retention, provide higher productivity, lower error rates and give users more work satisfaction. However, such narrowly focused reengineering may be inappropriate when more major problems lie outside the UI. |
From the literature it seems that an incremental migration strategy
is common. In addition to the case reports previously mentioned, Olsem
[18] and Brodie & Stonebraker [19] also make considerable use of the
approach. As such:
| Migrate Incrementally (aka Chicken Little). | |
| Context | A legacy system is to undergo reengineering to realise benefits for
the organisation. You wish to minimise the risk of: system outages during
cut-over; bugs in the target implementation; project cancellation; changing
requirements; and systems becoming unsupported. In addition, you need to
make best use of limited resources.
Although you expect reengineering to benefit the organisation, such an activity will, itself, carry risks which are difficult to predict, quantify and obviate. The scope of the project appears to be too large for the amount of resources available to support the necessary effort. If the project's timescales are stretched so as not to overload resources, requirement are more likely to change. If extra resources are acquired (for instance staff and equipment), project costs will rise and there will be an extra training burden. Changing requirements threaten to undermine reengineering efforts, yet you cannot ignore changing requirements since the credibility of the project, and hence its future viability, depends on satisfying users and business objectives. |
| Problem | What is the best strategy with which to execute a large, complex reengineering project? |
| Solution | Plan for a incremental, phased migration from the legacy to the target architecture. Decompose the legacy into sensible components. The reengineering of each decomposition becomes a phase in the project. Balance the effort involved in each phase with the available resources. Ensure that, throughout the project, there is an operational hybrid legacy/target system. Prioritise the order in which phases should take place based on the most pressing objectives being addressed first. |
| Consequences | Decisions on how best to decompose the legacy could be based
on any existing hierarchy of interfaces, logical code and data or the likelihood
of certain hardware or software components becoming unsupported. Alternatively,
tackle mission-critical phases first to raise the profile of the project.
If databases are migrated early, redundancy can be identified which can
help rationalise subsequent phases. Stand alone applications are more straightforward
to migrate than those which are tightly coupled with other systems. This
approach may lead to a quick success which helps the project's credibility,
but could overlook more critical migration candidates.
When some application has its interface, logic and data too tightly coupled for them to be individually excised, you may wish to wrap that part of the legacy. However, this will perpetuate the use of potentially unsuitable legacy components. Since the system is operational after each phase, the benefits of the project can be realised quicker than if the whole legacy were migrated and deployed at once. Also, bugs are easier to find and correct in a small component than in a large system. This reduces the project's risk and inconvenience to users. If, while balancing the resources and effort required for a phase, there is a significant disparity, consider subdividing or combining phases. Additionally, to make best use of different team skills, preparation for a later migration may be able to take place in parallel with the deployment of an earlier phase. Requirements creep is always a risk while reengineering. However, with each phase, new requirements can be accommodated throughout the project. If you suspect change is likely, you may wish to reengineer early those phases which are less likely to be affected. In addition, if each phase is delivered quickly, users may have less time to think up changes. Realising benefits early, reducing the impact of bugs and minimising the disruption of new and changing requirements gives the project credibility and will help secure its future funding. However, if circumstances change and the project is not to be continued, the end of each phase leaves the system operational and having prioritised the phases, the most important issues will already have been addressed. It is likely that there will be a number of dependencies between system components. Using gateways, you will be able to let disparate parts of the emerging architecture communicate. If you are ultimately aiming for a distributed system, early adoption of a middleware product allows you to provide consistent interfaces between components, so insulating the system from changes that occur behind the interfaces. Cutting over from the legacy to the target is risky. You may wish to let the legacy and target components coexist until it is convenient to change to the target. However, maintaining a legacy and target implementation of the same function is costly. Therefore, plan to retire legacy components as early as possible. For databases, this may be achieved by restricting updates to the new database and only conducting queries on the legacy - gradually the legacy will die. For a user interface, invest in training as near to deployment of the new interface as possible and make users aware that the old interface will cease to be operational beyond a certain date. In this way, users are less likely to forget what they have learned and revert back to the legacy interface. If they do revert back or are slow to adopt, they know they have a limited to time to conform and will feel encouraged to do so. |
| Related Patterns | When wrapping seem inevitable, consider Wrapped Service. Since the user community will experience change, you may wish to adopt Support the Change and to ensure you have captured existing requirements consider Reverse Forwards. |
| Known Uses | Plaisant et al. [15], Duncan & Lele [11], Hughes et al. [12], Olsem [18], Brodie & Stonebraker [19], Britcher [28] and Mohan [29] have all adopted incremental migration. |
It might appear obvious to try and understand a legacy system before
you reengineer it, but - as evidenced by Kutscha [17] who reports on cases
where a lack on understanding lead to problems - projects can and do proceed
without adequate background knowledge. Therefore, this next pattern is
drawn from the experiences of a number of authors who see reverse engineering
as an important activity before and during reengineering. To a certain
extent, the pattern is distilled from Museum
Manager and Low-Effort User
Interface Reengineering.
| Reverse Forwards (aka Know your Stuff or Know the Enemy). | |
| Context | You are about to start a reengineering project. Your team has a comprehensive
specification for the intended target system, but does not fully understand
the legacy or the domain in which the legacy operates.
Whilst following the specification without embellishment may satisfy your contractual obligations, it will not fully satisfy your customers/users. The specification is unlikely to cover all the subtleties of behaviour, knowledge and culture that have been evolving in the legacy over time. You want the reengineered artefact to take account of as many requirements as possible, but you need to start programming as soon as possible to meet project deadlines. |
| Problem | How can the reengineered artefact capture as many requirement as possible? |
| Solution | Learn as much as possible about the legacy and its domain before and during the execution of the reengineering project. First, encourage the team to study the legacy's code and documentation. Provide incentives for this at their job reviews. Observe users, interview domain/legacy experts and produce prototypes. Recruit one or more domain/legacy experts onto the project team. Hold workshops to educate the staff in the history of the legacy and the domain. |
| Consequences | Specifications make assumptions which may not be obvious to
everyone. A contrived and flippant example could be that the specification
for a new model of luxury motor car does not explicitly state that there
should be four wheels; one at each corner. The designers then assume that
they can make savings by having three wheels. Consumers reject the concept
and the product becomes un-sellable.
Taking time out to learn about the domain and the legacy through reading code and documentation, observation, interviews, workshops, and producing prototypes will add cost and time to the project. On the other hand, such activities should reduce the risk of missing requirements and will increase the quality of the reengineered artefact. Programmers are often reluctant to read documentation (particularly if they suspect it is out of date) and code (particularly if it is poorly structured or written in a language they are not familiar with). By providing incentives, they are more likely to invest the necessary time than if were merely instructed to do so. However, such incentives may add cost to the project. Since learning can take place throughout the project as well as at the beginning, you can start producing code earlier. As you understanding grows, you are better placed to ask the right questions and so improve your understanding further. However, you could have to re-work some aspect of the reengineered system after you discover an important requirement. On the other hand, you may well have adopted the concept of throwing prototypes away (an idea popularised by Brooks [8]). In which case, covering the same ground is already an established part of the project's methodology. An expert in the development team can provide instant and unsolicited feedback on issues. They are also less likely to provide misleading or incomplete advice, than the expert interviewee outside the team, since they have a professional interest in seeing the project succeed. Workshops are a useful means to deliver expertise to the team and also allow them to communicate their own knowledge to the group. However, they do require a substantial investment of time from all the staff. The issue of not adding extra time and costs to the project has not been fully resolved. Having made the investment, however, it is likely that it will pay off in less time being spent testing, debugging and seeking customer/user acceptance at the end of the project. |
| Related Patterns | Demeyer et al. [21] provide a reverse engineering patterns language to help understand the legacy quickly and effectively. Closely related patterns are Museum Manager and Low-Effort User Interface Reengineering. |
| Known Uses | Tilley & Smith [6], Fanta & Rajlich [16], Bray & Hess [20], Plaisant [15], Ruhl & Gunn [30] and Adolph [7] all advocate reverse engineering before and/or during a reengineering project. More generally, Sneed [31] equates a thorough understanding of the domain and existing systems to project success. |
Resistance to change may be particularly prevalent in reengineering
projects, more so than in new system development, since there was already
some system in place that users had become comfortable with - warts
an' all.
| Support the Change. | |
| Context | You are reengineering a system. The project will affect the User Interface
(UI) and/or functionality. The end result will affect the users' working
practices. User acceptance is important for the success of the project.
Change is necessary, but the users will be affected. If the users do not support the change the project will suffer during execution and deployment. The users can offer valuable input to the project, but tapping their expertise is difficult, time consuming and may involve having to satisfy too many additional requirements. |
| Problem | How can change be managed during reengineering? |
| Solution | Involve the users to gain their acceptance and contributions. Ensure you understand the legacy and the domain. Make it clear what the project will deliver, for instance no new functionality; just a change in architecture. Adopt a phased migration strategy. Second users to the development team and interview others. Produce prototypes and let users provide feedback. Train users away from their normal working environment. Minimise changes to the system's external views wherever possible. Test the system extensively at the end of each phase and before deployment. |
| Consequences | People are often reluctant to change. The effect of change will
manifest itself in people finding endless ways to rubbish the new and applaud
the old, reverting to old ways, committing sabotage and even having to
take time off through a stress related illness. Resistance will happen
so it is best to be prepared.
You will gain more credibility with users if you understand the domain and the legacy system. However it may take time to obtain this status and it will be easy to loose if subsequent problems arise. Making it clear to users what to expect serves two purposes. It lessens the shock of change by making them aware that change will happen. By being explicit about the scope of the change, they will also be less inclined to insist on new features which could affect the main objectives of the project. The phased approach introduces change gradually which should lessen the impact on users. If users are involved and consulted, they gain a sense of ownership and empowerment. They will also be less inclined to offer good advice after things have gone wrong. However, it is unlikely that all users can be directly involved in the project and those that are not may feel disenfranchised - unless they feel their seconded colleagues are their representatives. Prototypes can show users what is possible and what has changed well before they are faced with having to adapt during their normal work. When faced with a new system users may feel intimidated. By providing training they can become familiar with the new situation away from their normal working environment and pressures. Changing UIs or printouts may be unavoidable, but if the changes can be minimised the users will provide greater acceptance of the new system. When the users are disrupted by errors in the new implementation, they will be less inclined to trust the system, even when the errors are fixed. By comprehensive testing, the risks of them encountering problems are reduced. Also, since an incremental migration strategy is being adopted, bugs are easier to find and quicker to fix in each small new release. Whilst coercion may be useful in some circumstances, for example offering rewards in return for supporting the project, it may be less appropriate here. Firstly, rewarding users for silence and compliance will not encourage positive support for the project, whereas rewarding developers for enthusiasm and action will. Users are less well placed to take action and artificially heightened enthusiasm may overload the project's requirements. Secondly, it may be more expensive to reward users than developers since there will probably be more users. Finally, for some, rewards will not affect the perceived stress that change will create. |
| Related Patterns | For the phased migration consider Migrate Incrementally. When dealing with UIs consider Low-Effort User Interface Reengineering and to gain system and domain understanding consider Reverse Forwards. |
| Known Uses | Tilley & Smith [6], Plaisant [15] and Duncan & Lele [11] have all taken account of users' natural resistance to change. |
| Name | Problem | Solution |
| Museum Manager | How can the archaic legacy code be migrated to a modern format? | Get the team to respect the legacy and understand their tools. |
| Reengineer for Interaction | How should the migration from batch to interactive operation proceed? | Build a UI, extract the logic and design a data model to support tolerant, persistent editing of multiple work products. |
| Buy & Build | How can the legacy system be migrated to commercial off the shelf applications? | Involve external and internal experts in the phased migration to the new products. |
| Wrapped Service | How can duplicated functionality be made into a common service? | Wrap the service to provide a common interface for all the applications to use. |
| Low-Effort User Interface Reengineering | How can the UI be improved with minimal effort? | Understand the system and users in order to prioritise incremental action. |
| Migrate Incrementally | What is the best strategy with which to execute a large, complex reengineering project? | Plan for a incremental, phased migration from the legacy to the target architecture. |
| Reverse Forwards | How can the reengineered artefact capture as many requirement as possible? | Learn as much as possible about the legacy and its domain before and during the execution of the reengineering project. |
| Support the Change | How can change be managed during reengineering? | Involve the users to gain their acceptance and contributions. |
The "rule of three" is a common criterion in the patterns community to determine the validity of a pattern. If the pattern has been seen to be successful in at least three independent cases, then it can be said to have some validity. Whilst the five case patterns are specific to the single case study from which they are drawn (with the exception of Wrapped Service which comes from two reports), the three subsequently derived patterns have sufficient known uses to gain some validity. However, the intention of those first five patterns is to show how a lengthy case study could be re-expressed into a more consistent, reflective and potentially useful form.
It is reasonable to argue that something has been lost between the verbose case reports and the case patterns. Through the bias of the authors involved in this paper and the inevitable loss of detail, some aspect of the project important to a reader may be lost. Of course, the same could be said of the the original case report since one paper is unlikely to have included all the complexity of the actual project. Its authors will have had their own view of and prejudices concerning what really happened. In addition, the specific context of a specific project is unlikely to recur very often. To make use of the lessons learned in a case report, the reader must impose their own experience, values and concerns onto that context and, therefore, abstract still further. So, abstraction is necessary and inevitable. With each abstraction some detail or meaning has been lost, but at some level of abstraction the situation becomes accessible and useful to the maximum audience - see Figure 2.
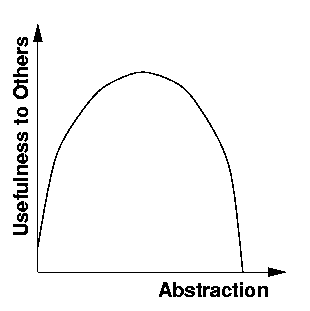
Figure 2 - Usefulness as a Function of Abstraction
In this paper a comprehensive pattern language has not been proposed, although some relationships between patterns have been included. Instead we present a collection of loosely coupled issues that have been derived from literature. In parallel, the authors are mining patterns from industrial collaborators through interview and observation [23, 24, 25]. Ultimately, there will be sufficient patterns and relationships between patterns to form a language.
Some of the issues raised are far from exclusively related to reengineering, for instance managing change and phased project schedules. However, they provide examples of implementation considerations that do arise during a reengineering project.
Although there is large body of reengineering literature, surprisingly little is founded on case material. The act of writing this paper has confirmed the assertion that a great deal of time can be expended trying to find best practice from literature. We conclude that more work is required to document good reengineering practice in an accessible, consistent form and the authors hope that the community would adopt patterns as a medium for encapsulating expertise.
We would encourage others to comment on the patterns presented here, particularly if they know of instances where they have seen similar solutions applied to similar problems in similar contexts. In time, and if more people can abstract their experiences of reengineering into a case patterns format, variants on those described here and elsewhere can be seen to recur. In this way, their levels of abstraction can be fine tuned and the patterns can attain more validity by having been observed in real-world, industrial strength reengineering projects.
The problems with the rail scheduling system (originally installed in 1971) were that it was difficult to hire staff interested and competent in its archaic programming language, the hardware was difficult to maintain, demands on the system were due to increase beyond its current capabilities, there was much redundant code in the legacy and it had performance and memory limitations.
The reengineering project was predominantly staffed by external people - a minority of the team had experience of the legacy. They had 12 incremental development phases, the first two were relatively simple and were intended as pilots to test tools and methodology. It later transpired that these pilots were not large enough to fully test the approach and serious flaws were only discovered as the project was ramped up.
The first problem discovered was that effort estimates were overly optimistic. Experienced personnel - who assumed that the developers were familiar with the legacy, methodology & CASE tool and domain - had arrived at the estimates. Next, the original code was designed to squeeze the best out of the limited memory of the old hardware. This means it incorporates coding tricks which makes finding useful domain specific logic difficult. Adolph also found that a significant number of work packets failed their design reviews because they did not capture all the functional requirements contained in the legacy code. This was due to the documentation being out of date and the code being difficult and tedious to read. He concludes that programmers have a natural reluctance to read old code. The solution applied was to make all staff read the code and to make this part of their job performance review. Also, a senior developer painfully mapped the legacy and provided lunchtime seminars on the theory and history of railways signalling and the legacy itself. A train set was even purchased to help demonstrate principals. Yet another problem was that designers wanted to add elegant new features or redesign inelegant algorithms. This introduced delays and risk since they were adding untried complexity and throwing away 20 years of operating experience. It also meant creating new test plans. Management eventually prevented this by introducing a project directive that no features of the legacy were to be changed unless they directly reduced the cost of the project - not necessarily the short or long term cost to the customer.
Cadre's Teamwork CASE tool was used for analysis and design. It was deployed on PCs since more staff were familiar with these than UNIX systems. Unfortunately, the PC version at that time wasn't as comprehensive as that for UNIX. Overall, they found the tool invaluable for coordinating the work of the 15-man team. However, they discovered that they could not achieve the expected productivity gains due to most staff being unfamiliar with the tools and techniques, despite having been on training courses. Adolph concludes that staff need front line experience with a tool to appreciate potential pit falls. Adolph recommends having a dedicated tool smith to maintain the CASE tool rather than giving the responsibility to a developer and eroding their output.
Adolph reflects that a project's enemy is risk from the staff's inexperience, changing requirements, tool capability, target platform availability and the reliability of 3rd party software. He also feels that it is wrong to assume that reengineering is easier than new system development. The assumption can only hold if the development staff are intimately familiar with the legacy.
In summary, the project was late and over budget, however Adolph reports the product was "high quality", met customer requirements and was able to be quickly deployed into operation.
The paper begins by contrasting batch and interactive systems. The authors note that batch systems have a predetermined order of computational steps and there is little need to cleanly decouple or incrementally repeat stages. The ability to run independent concurrent jobs is generally not a concern. Batch systems accept one or more complete inputs and produce one or more complete outputs before terminating. Human intervention in generally not expected or accepted. Once the process begins, there is no need for external influence. Interactive systems, on the other hand, do expect humans to participate throughout computation. A batch system is invoked for a single job and have a finite duration. An interactive application can be invoked for multiple jobs, for example word processors can act on multiple documents, and the session can last indefinitely. Also, no internal data structures persist between batch invocation. This implies that even a small change to the input stream necessitates a re-run of the job, whereas incremental changes can be made to the interactive work product.
DeLine et al. then move on to consider the implementation issues of migrating from batch to interactive. Early on in the reengineering project, strategic architectural decisions need to be made. For instance the interactive system could be State Driven where the computation and UI (User Interface) access the data as and when they need to. Alternatively, it could be Event Driven where the computation and UI are notified when there are changes to the data. This permits looser coupling between the UI and the computational subsystem. Furthermore, there can be a internal shared data representation if the system is to be closely coupled and a fast response time is required. On the other hand, an external shared data repository introduces a performance penalty but provides the opportunity for looser coupling. A special case would be where the shared data is encapsulated into an object. Here the operations of the object provide a common, symmetrical API for the UI and computational subsystem.
The authors go on describe a number of other issues. For instance, a batch system's inputs are complete and fixed at invocation, however, the interactive system's inputs can be created and modified at any time and the system must, therefore, be tolerant of missing or incomplete data. The interactive system may also be required to support user-defined modifications and deletions of portions of the work product - functionality not required of the batch application.
With respect to memory management, batch applications are seldom persistent and do not incorporate delete operations. As such, they do not have to be overly concerned about memory leaks or track and reuse memory. However, since interactive systems can be long lived and can provide editing facilities, they need to manage themselves carefully to avoid running out of free memory.
The structured form of the batch input means that the computation can be well structured into sub-computations or phases. Because the user drives the interactive inputs, fewer assumptions can be made about the ordering or repetition of the computation. With interactive systems, the re-computation and processing of partial data can lead to the invocation of code in new contexts and the entry assumptions made by batch code may no longer hold. These scenarios all need to be checked.
A batch system's functionality can be expressed as monolithic processes (for instance input -> computation -> output). However, the lower level functionality called for by the interactive UI needs to be excised from the code and made available as individual computations. In addition, the data needs to be structured to handle multiple work products. For instance, the same code may be independently used for different work products during the same session and data for each needs to be differentiated to avoid corruption.
The batch system generally reports on errors in the inputs and can either tolerate or terminate - reporting its actions to a log file. The interactive system can be designed to prevent errors, for instance menus with predefined options. In addition, the interactive system should generally recover from errors and allow the user to correct the input. Also the information in, and context of, the error messages needs to be different, for example line numbers may not be relevant for an error message in an interactive session.
Their legacy handled sales, marketing, engineering, operations, finance and customer support. It had undocumented source code and they had to hire consultants for modifications. This was "tedious and expensive". The result was that the consultants were customising "spaghetti code" and creating more complexity with each iteration. They had 12 full time employees supporting the legacy - an HP mainframe with mostly FORTRAN code.
Telogy's reengineering efforts began in 1992. Although there were no off-the-shelf packages ideally suited their business, they estimated that building a new system from scratch would take 4 years and cost $24m. They compared some of the packaged solutions that were available and decided on Sybase as their Relational Database Management System (RDBMS). Their decision was based on Sybase's connectivity and openness that provided a greater selection of third party applications. Additional packages bought were a customer resource package from Aurum software and a manufacturing resource planning package from TXbase. These packages were about a 75% fit for Telogy. Hardware chosen was Sun Unix database and application servers with X-terminals. In addition, there were to be desktop PC clients.
They incrementally migrated to the new architecture via six phases - each phase focused on one function of the business. The resultant system was reasonably fault tolerant through the use of back-up servers and clients as well as redundant hubs in their network. They outsourced the customisation and integration of the new packages by employing an Indian company, HCL, who had USA offices. This avoided having to hire expensive, local contract staff. Gradually systems maintenance was handed over to Telogy staff.
The first stage in training the Telogy staff was to document existing processes as well as the evolving system. The documentation facilitated training and was also used as part of the company's ISO9000 accreditation.
On a 3 year basis, project costs were $4.8m, versus a budget of $4.5m. Overruns were attributable to extra customisation, the turnover of users and changing requirements. Although their basis is not clear, total benefits were claimed to be $9.45m.
The resultant context was: internal and external sales could work together to service customers with no need for hand-offs between them; order cycle times reduced; improved responsiveness to customers has increased sales by an estimated 20%; less paper work; electronic ordering via web; Sybase triggers exception conditions (for instance low stock, overdue deliveries) and provides quicker responses and shorter cycle time; the introduction of bar code readers increased the accuracy of data; automation of sourcing, purchasing and quote handling by the integration of fax and voice data systems; customers can query orders via the voice data network; former stand-alone PCs are now networked and centrally administered making significant savings and improving communications; and better executive reports were available.
The implementation issues that arose were:
In summary, Telogy gained competitive advantage by purchasing packages quicker than they could develop in-house. They obtained strategic advantage by tailoring these packages to perform tasks their competitors could not. In addition, they shared risk with their vendors by not having to be solely responsible for updates and maintenance.
They distinguish between course grained encapsulation, that is wrap the whole legacy, and fine grained where some functionality of the legacy is extracted and made into a common service.
In their work Hughes et al. have used Iona Technologies' Orbix middleware ORB (CORBA compliant). They adopted a ten step methodology on a pilot project. This included: identifying the application and services for reengineering by considering costs and benefits as well as the impact of the new architecture (the ORB must be compatible with the systems and languages); identify the tools needed (for example reverse engineering tools); decide on the reengineering environment (the original, reengineering and deployment environments may all be very different); build the new service which may be newly developed, from a third party or a wrapped portion of the legacy; reengineer the legacy code to make it use the new service; and finally carry out testing and document the system.
The lessons Hughes et al. learned were:
The lessons Sneed and Majnar learned were:
Their strategies and findings were:
For system access they found they could make life easier for users by bringing distant equipment closer, opening up frequently locked rooms, repairing damaged equipment, increasing system speed and reliability and simplifying access procedures. Using colour, sorting and grouping field, highlighting, mixing upper & lower cases, bolding and removing obsolete information and obscure codes can help data display. Improved data entry can reduce error and speed up performance. To achieve this they removed instances where data was being entered twice, displayed default values, limiting cursor movement to editable fields, introduced touch screens, provided more visible cursors and used consistent key sequences. Consistency was addressed by considering common action sequences, terms, units, layouts, abbreviations, spelling, capitalisation and colour. The results were faster learning, higher productivity, lower error rates and better retention. Error and system messages were improved by making them more specific and providing constructive guidance. Adopt a positive tone and avoid unnecessary information, for example error codes. Again, consistent message format, appearance and placement helps users. Discussions with users and feedback from questionnaires identified additional functionality, examples are graphical representations and information visualisation to better present a given screen.
Plaisant et al. recommend providing a schedule and a statement of the effort involved, as well as ranking recommendations in terms of payback. They recognise that reengineering is complex and risky and has the potential to disrupt users. They warn that such narrowly focused reengineering may be inappropriate when more major problems lie outside the UI.