



Next: Temporal Join Conditions
Up: Using IP-Tables for Selectivity
Previous: Using IP-Tables for Selectivity
So far, the main purpose of IP-tables has been the efficient support
for the optimisation of partitioned temporal join processing. In this
chapter, we want to show that the scope and the applicability of
IP-tables goes beyond that. In fact, IP-tables can be considered as a
general metadata-structure that can be used in a wide
range of temporal query optimisation
techniques, especially in those that require (semi-) optimal
partitioning of temporal data over a timestamp
attribute, such as physical data partitioning or balancing temporal
index structures.
In this chapter, we concentrate on an optimisation issue which is not
directly connected to temporal data partitioning but that can
nevertheless be efficiently supported by IP-tables, namely the
selectivity estimation of temporal conditions. Selectivity estimation
is a powerful way to predict the result sizes for many operations. On
the basis of these predictions, an optimiser can then take many
performance-relevant decisions, such as
- Which algorithm should be used to perform the respective operation
most efficiently? Often there is a wide range of algorithms available,
with some being suitable for low selectivities, others for high
selectivities. The join operation is a good example for this: in
chapter 3 we saw a variety of join algorithms with the
nested-loops approach being suitable only for high selectivities
whereas sort-merge or hash algorithms were more efficient in the case
of low selectivities.
- Which is an efficient order in which operations should be processed?
A query that incorporates various operations is often translated into
an operator tree. In this tree, operations with low selectivities
(i.e. small result sizes) are moved near the leaves (i.e. these
operations are performed first) and operations with high selectivities
towards the root. This has the advantage that the initially-processed
operations already discard large amounts of data and therefore reduce
the sizes of the intermediate results. This can reduce the overall
performance by a considerable amount.
- How many resources are required to process the query? From
a system's point of view, the optimiser might want to consider the
impact of the query on the system's overall performance: if the query
is `heavy' (i.e. very resource-consuming), for example, then other,
`lighter' queries might be granted priority.
Furthermore, an optimiser could warn a user if a query result size
will be huge, and therefore possibly useless or not what has been
intended; the user can then think of rewriting his/her query without a
useless query being processed by the system. This is particularly
relevant in the context of data mining or decision
support systems which are likely to
issue complex, ad-hoc queries involving huge amounts of data.
We restrict ourselves to the discussion of selectivities of temporal
join conditions as these have been the focus of major parts of this
thesis. This restriction is also sufficient to prove the wide
applicability of IP-tables. As defined in
section 3.4, the selectivity
factor (or
selectivity , for short) of
a join 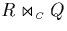 is
is
In section 11.2, we classify temporal join
conditions. Actually this is a summary of what was discussed in
section 4.1 but this time with a slightly different
emphasis. In section 11.3, we derive equations that
allow either the exact calculation, or a reasonably accurate
estimation of the size of temporal join results and therefore also the
selectivity of the corresponding temporal join condition.
Next: Temporal Join Conditions
Up: Using IP-Tables for Selectivity
Previous: Using IP-Tables for Selectivity
Thomas Zurek