It was mentioned previously that a data structure with commuting sub
directions will exhibit some redundancy, in that we can predict in
advance which nodes are to be shared, and avoid repeating
computation. Ideally, we want to predict how much computation can be
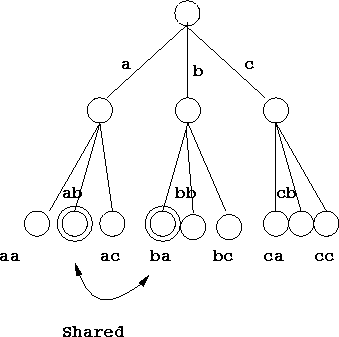
saved by this system. Consider a tree of degree 3, where two of the
directions commute. If we consider the first two levels of the graphs
(fig. 6.1), we have one shared node on the second level. If
we then extend the structure below this level, the whole of that sub
tree will be shared, so a least ![]() of the whole structure
will be shared. A similar argument shows that for 4 directions, two of
which commute, at least
of the whole structure
will be shared. A similar argument shows that for 4 directions, two of
which commute, at least ![]() of the structure will be
shared. These figures seem rather small, but in fact the amount of
redundancy greatly increases as we consider deeper trees.
of the structure will be
shared. These figures seem rather small, but in fact the amount of
redundancy greatly increases as we consider deeper trees.
The implementation was used to calculate the number of nodes. It was found that for an unbalanced tree of depth 8, with the above commutation properties, that only 1701 nodes out of a possible 2069 are distinct. This suggests that for this example, which is not balanced, that the node sharing figure is closer to one fifth. We should therefore be able to calculate a better estimate, if only for a balanced structure with the required commutation properties.
In general, consider a situation where we have a set of directions
D, with commutation conditions on some of them, and an ordering on
them all. Then each direction d will have a set Pd of directions
that can legitimately precede it in a normalised path name. Then if
nl,d is the number of paths of length l that conclude with
direction d, then we can express nl,d as ![]() .
.
This will lead to a set of recurrence relations for the number of directions in each level of the graph. For our example outlined above, this gives us a total, for level l of:-
If the call graph is balanced, so that it is the same depth n at all
points, we can compute the approximate number of nodes in it, simply
by ignoring the small ![]() term and summing from 1 to
depth n. This gives an approximate value of:-
term and summing from 1 to
depth n. This gives an approximate value of:-
We can compare this with the number of nodes in a graph with no
commutativity, a figure of ![]() . Thus the ratio of nodes
in the non commuting structure, to the nodes in the commuting
structure is:-
. Thus the ratio of nodes
in the non commuting structure, to the nodes in the commuting
structure is:-
Where ![]() , or
approximately 0.8453. The above estimate, shows that as n
increases the proportion of computation we can save by exploiting some
of the commutativity, increases also. In fact this proportion is
unbounded as we increase the depth of the tree. This will be the case
in other examples. So exploiting as much commutativity as possible is
worthwhile, especially for deep function call graphs.
, or
approximately 0.8453. The above estimate, shows that as n
increases the proportion of computation we can save by exploiting some
of the commutativity, increases also. In fact this proportion is
unbounded as we increase the depth of the tree. This will be the case
in other examples. So exploiting as much commutativity as possible is
worthwhile, especially for deep function call graphs.