



Next: Dependency on m
Up: Experimental Evaluation
Previous: The Basic Data Set
In chapter 9, several families of partitioning strategies
have been discussed. In this section, we want to obtain some insight
about their performance characteristics.
For that purpose, they were used to process the three joins , 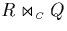 and
and ![[*]](foot_motif.gif) where the join condition C simply requires
the timestamp intervals to intersect. We note that
the three joins have the profiles , and , i.e.
where the join condition C simply requires
the timestamp intervals to intersect. We note that
the three joins have the profiles , and , i.e.
- the join has a periodic profile
(figure 10.4),
- the join has a partially periodic profile
(figure 10.5),
- the join has a non-periodic profile
(figure 10.6).
In total, we tested the following 11 strategies; each of them has been
discussed in chapter 9:
- 1.
- Uniform Lifespan :
this strategy uniformly partitions the joint lifespan of the participating
relations (see section 9.1.1).
- 2.
- Uniform Range :
this strategy uniformly partitions the joint range of the participating
relations (see section 9.1.2).
- 3.
- Uniform Startpoints Span :
this strategy uniformly partitions the joint startpoints span of the
participating relations (see section 9.1.3).
- 4.
- Basic Underflow :
this is the basic underflow strategy as described in
section 9.2.1.
- 5.
- Basic Underflow with b/o : this is the basic underflow strategy
(section 9.2.1) used in conjunction with the
black-out preprocessing strategy
(section 9.4).
- 6.
- Primary Underflow :
this is the variation that applies underflow partitioning to the
primary subfragments only (section 9.2.2).
- 7.
- Primary Underflow with b/o : this is the variation that applies underflow partitioning
to the primary subfragments only
(section 9.2.2). used in conjunction with
the black-out preprocessing strategy (section 9.4).
- 8.
- Basic Minimum-Overlaps :
this is the basic minimum-overlaps strategy as described in
section 9.3.1.
- 9.
- Basic Minimum-Overlaps with b/o : this is the basic minimum-overlaps
strategy (section 9.3.1) used in conjunction with
the black-out preprocessing strategy
(section 9.4).
- 10.
- Primary Minimum-Overlaps : this is the variation that applies minimum-overlaps
partitioning to the primary subfragments only
(section 9.3.2).
- 11.
- Primary Minimum-Overlaps with b/o : this is the variation that
applies minimum-overlaps partitioning to the primary subfragments only
(section 9.3.2). It is used in conjunction
with the black-out preprocessing strategy
(section 9.4).
We note that this list is not complete: in practice there can be many
more partitioning strategies, e.g. further variations within the three
families or some that take system-specific performance characteristics
into account.
Table 10.3 shows the performance results for
the strategies when being applied to the three joins and using a
parallel and a single-processor hardware architecture. In order to
guarantee a fair comparison between the strategies, the parameters
X, XR and XQ for the underflow and minimum-overlaps strategies
were chosen to produce m=16 fragments / partial joins - the same
number as the uniform strategies. We note that in the case of the
parallel architecture (, ) this means that each processor
processes one partial join. For the black-out preprocessing strategy
we used the average of the 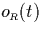 values in an
IP-table I(R) to be the respective threshold value Y ,
i.e.
values in an
IP-table I(R) to be the respective threshold value Y ,
i.e.
We will now look at certain issues that are `hidden' within the many
numbers in table 10.3. First, we want to get
a general idea about the strategies, irrespective of the type of join.
For that purpose, each of the numbers in
table 10.3 is normalised in the following
way: the performance results of the uniform lifespan strategy
are respectively used to represent a general value 100. Columnwise,
the times are converted into ratios with respect to the time achieved
with the uniform lifespan strategy:
For each of the two architectures, we then take the average of the
three performance results per strategy. This normalisation guarantees
that each join contributes an equal share to the average and it is not
the most expensive join that contributes most. Figure 10.7
shows the averages for the parallel and figure 10.8 for the
single-processor architecture.
In the case of the parallel architecture, the primary underflow
strategies are the clear winners, causing only around a third of the
costs compared with the uniform strategies. The other underflow and the
minimum-overlaps strategies end up in the area between 50 and 60. Apart
from the quantitative aspect, this result is not surprising as the
principal goal of the underflow strategies is to achieve a good balance
between the fragments, regardless of the number of overlapping
intervals. This means that all partial joins are more or less of equal
sizes - a fact that is beneficial in the context of parallelism. The
minimum-overlaps strategies make concessions with respect to the load
balance in order to achieve a minimum-number of overlaps. These
concessions obviously do not pay off. An interesting difference between
the four underflow and the four minimum-overlaps strategies is that the
primary underflow variations perform better than the basic strategies
whereas the opposite relationship can be found between the
minimum-overlaps strategies. In theory, one would expect the primary
strategies to perform better in both cases because they take various
aspects of the cost model into consideration (see discussions in
sections 9.2.2
and 9.3.2). To explain the contrary effect
in the case of the minimum-overlaps strategies, we have to look at the
absolute figures in table 10.3: the primary
versions of the minimum-overlaps strategies are also better for the
joins and but are somewhat far behind in
the join . This `destroys' an otherwise favourable average
value as used in figure 10.7.
There are two more conclusions that can be drawn from the diagram in
figure 10.7:
- it confirms what we already expected in
section 9.1, namely that there is not much difference
between the uniform strategies;
- there does not seem to be much benefit that can be drawn from
black-out preprocessing if there is a benefit at all. We will return
to this problem in section 10.9 where experiments are
conducted to analyse the black-out preprocessing strategy in more
detail.
Now, we turn our attention to the figures obtained from the
single-processor architecture (figure 10.8). Here, the
scene looks quite different: the underflow and minimum-overlaps
strategies perform at around 82-86% of the costs of the uniform
strategies. The basic minimum-overlaps strategy using black-out
preprocessing is a narrow winner. Through the experiments in
section 10.3, we will see that this scenario changes for
higher values of m.
Finally, the question arises whether the optimisation process itself
is efficient. It would not be worth while to optimise the partitioning
if the optimisation itself imposed considerable costs.
Figure 10.9 shows the average elapsed times that were spent
on the optimisation itself. The hardware platform was a Sun SPARC
SS-20 computing server with two processors. The uniform and underflow
strategies required less than 2 seconds, whereas the minimum-overlaps
strategies took around 16 seconds which is still relatively low in
comparison to the join processing times in
table 10.3.
Figure:
The profile of (``join 1'').
|
Figure:
The profile of (``join 2'').
|
Figure:
The profile of (``join 3'').
|
Figure:
Performance result averages for the three joins on the parallel
architecture.
|
Figure:
Performance result averages for the three joins on the single-processor
architecture.
|
Figure:
Average optimisation costs (in sec.) for all the experiments conducted
in this section.
|
Next: Dependency on m
Up: Experimental Evaluation
Previous: The Basic Data Set
Thomas Zurek