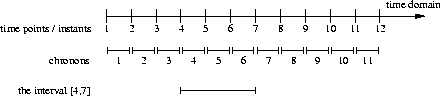We now want to define some basic concepts and technical terms that are used in the context of relational temporal databases. We thereby restrict ourselves to the concepts that are relevant for the remainder of this thesis. We adopt the definitions that have been published by the group of researchers during the process of designing TSQL2, e.g. in [Jensen et al., 1994a]. This, however, does not imply that any of the work that is presented here and in the remainder of this thesis is specific to TSQL2. We use these definitions because they can be regarded as being well established among the temporal database research community for the following reasons:
As motivated in the introduction, temporal databases store
time-dependent data. In the context of the relational data model this
means that temporal data objects - these can be either tuples or
single attribute values - have an associated timestamp
which is a time value, such as a date or a time
interval. The most frequently suggested combination - and the one we
adopt - is to have temporal relations with
timestamped tuples . The advantage of this
choice is that this goes well with conventional relational structures:
a tuple-timestamp can be regarded as `just another attribute', at
least in some aspects![[*]](foot_motif.gif) . Temporal relations can even adopt first normal
form (1NF) on which many
commercial database management systems rely. Alternative approaches,
such as timestamping attribute values as
in Gadia's Homogeneous Relational Model [Gadia, 1988], may not
be capable of directly using existing relational query evaluation
techniques or storage structures which depend on atomic attribute
values. Consequently, many new evaluation techniques would be required
and would have to be implemented, always bearing in mind that
conventional query evaluation performance should not be penalised in
the redesigning process. Given these problems and the fact that
radical changes in well established implementations are highly
unlikely, it is more realistic to discard such non-1NF approaches.
. Temporal relations can even adopt first normal
form (1NF) on which many
commercial database management systems rely. Alternative approaches,
such as timestamping attribute values as
in Gadia's Homogeneous Relational Model [Gadia, 1988], may not
be capable of directly using existing relational query evaluation
techniques or storage structures which depend on atomic attribute
values. Consequently, many new evaluation techniques would be required
and would have to be implemented, always bearing in mind that
conventional query evaluation performance should not be penalised in
the redesigning process. Given these problems and the fact that
radical changes in well established implementations are highly
unlikely, it is more realistic to discard such non-1NF approaches.
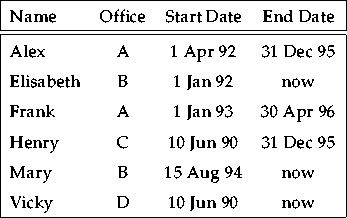
Figure 2.1 shows a temporal relation Staff that is
supposed to hold members of a university department, the numbers of
their respective offices and a timestamp that indicates the time period
in which they worked in the department. A special identifier
`now' is used to denote the current moment. The treatment
of `now' is a separate research topic, see e.g.
[Clifford et al., 1997]. For our purposes, we imagine that `now' is replaced
by the current date whenever an operation looks at the data.
In general, timestamps of a temporal relation are defined over a certain time domain which is often represented as a time line . Elements of the time domain are timepoints or instants . Although time itself is generally perceived to be continuous, most temporal data models that have been proposed are based on a discrete model of time. Such models use a non-decomposable time interval, called a chronon , as a basic unit of minimal duration. Starting with an initial time point, following timepoints appear at the distance of a chronon from its predecessor. An interval is the time between two timepoints, a start- and an endpoint. Alternatively, it can be interpreted as a contiguous set of chronons.
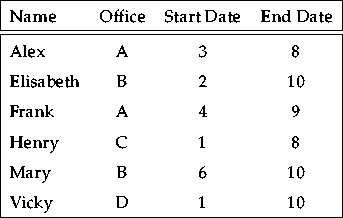
Figure 2.2 illustrates the relationship between the time domain, timepoints, chronons and intervals. It uses integers to refer to time. This not only simplifies the notation but also avoids the problem of incorporating into our examples the granularity of the time line, i.e. the duration of a chronon: a second, a minute, a day etc. This depends on the actual application. As an example, see figure 2.3 which shows the relation Staff using an integer time representation, assuming that now is at timepoint 10. Below we will describe further details of the choices we make.
As already mentioned, we adopt a discrete time domain. This choice does not affect the concepts that are developed and discussed in this thesis but simplifies many notations and discussions. Apart from that, one can find several practical arguments for the preference of a discrete over a continuous model [Jensen et al., 1994b]: firstly, clocks usually show time in terms of chronons - usually seconds or minutes. Secondly, time references in natural language are normally compatible with the discrete model. Thirdly, the concepts of chronon and interval allow us to naturally model events that are not instantaneous but have a duration. Finally, any implementation of a temporal data model must necessarily have some discrete encoding for time.
As indicated above, a timestamp can be a date, an event or an
interval. We adopt the most frequent choice and use interval
timestamps. Intervals have proved to be the most versatile
representation of time: intervals and relationships between intervals
can adequately express almost any time reference in natural language.
For that reason, they have been used not only in many temporal
database applications but also for many techniques in natural language
processing [Allen, 1983]. We usually represent intervals by referring
to their start- and endpoint. In the special case that those points
are identical the interval has a duration of 0 chronons and therefore
depicts a time instant (timepoint) .
Otherwise the interval has a duration greater than 0 and refers to a
contiguous time period.
In notational terms, we denote an interval by squared brackets surrounding the respective start- and endpoint:
| |
(3) |
![]()
[ts,te] is also called a closed interval . Sometimes it is convenient to exclude the start or the endpoint or both. Such intervals are said to be left-open , right-open or open , respectively, and are denoted by
We will mainly use the [ts,te] type and use the others whenever it helps to simplify the notation.
For our purposes, we assume that each tuple r of a temporal relation R has at least one interval timestamp . If there is more than one timestamp per tuple then one of them is regarded as the designated one, e.g. the one that is used in a join condition or the one that is used for partitioning the data; the others are treated as conventional attributes.
In summary: each ![]() has an interval timestamp. The startpoint
of the timestamp is referred to as
r.ts and the endpoint as r.te ,
i.e. the timestamp is the interval [r.ts,r.te]. Further
notations will be introduced in the stages in which they are required.
has an interval timestamp. The startpoint
of the timestamp is referred to as
r.ts and the endpoint as r.te ,
i.e. the timestamp is the interval [r.ts,r.te]. Further
notations will be introduced in the stages in which they are required.