




The Multithread Library |
11 |
 |
The features described in this chapter apply only to the Solaris 2.x environment.
This chapter contains the following sections:
Multithread Environment for Pascal
Compiling and binding a multithreaded Pascal program requires the following:
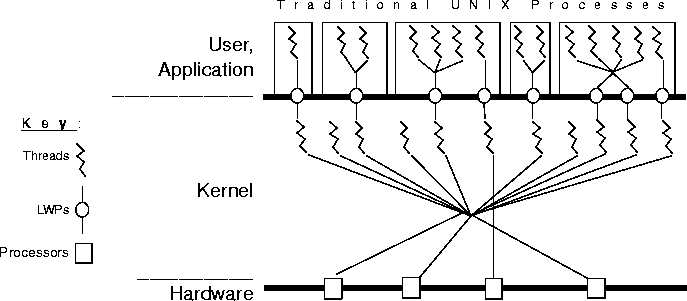
Figure 11-1 Thread Interface Architecture
The libthread multithread library schedules LWP usage for user threads. When a user thread blocks due to synchronization, the LWP transfers to another runnable thread through co-routine linkage and not by system call. If all LWPs block, the multithread library makes another LWP available.
Each LWP is independently dispatched by the kernel, performs independent system calls, and may incur independent page faults. On multiprocessor systems, LWPs can run in parallel, one at a time per processor. The operating system multiplexes the LWPs onto the available processors, deciding which LWP will run on which processor and when. The kernel schedules CPU resources for the LWPs according to their scheduling classes and priorities; the kernel has no information about the user threads active behind each process.
Threads share access to the process address space, and therefore their accesses to shared data must be synchronized. Solaris threads provide a variety of synchronization facilities that use various semantics and support different styles of synchronization interaction:
The following two Solaris threads routines are the most commonly used routines for mutual exclusion:
The following three Solaris threads routines are the most common routines for handling conditional variables:
The following three Solaris thread routines are the most common routines for handling semaphores:
sema_init(3T) initializes the semaphore variable.
sema_wait(3T) blocks the thread until the semaphore becomes greater than zero, then decrements it--the P operation on Dijkstra semaphores.
sema_post(3T) increments the semaphore, potentially unblocking a waiting thread--the V operation on Dijkstra semaphores.
The following routines are the most commonly used for readers/writer locks:
When a matrix-multiply operation is called, it acquires a mutex lock to ensure that only one matrix-multiply operation is in progress. The MatrixMultiply program uses mutex locks that are statically initialized to zero. A requesting thread checks whether its worker threads have been created. If its worker threads have not been created, the requesting thread creates them.
In the MatrixMultiply program, once its worker threads are created, the requesting thread sets up a to_do counter for the work and then signals the worker procedure via a conditional variable. Each worker procedure picks off a row and column from the input matrix, then the next worker procedure gets the next item, and so on.
The matrix-multiply operation then releases the mutex lock so computation of the vector product can proceed in parallel, with each processor running one thread at a time.
When the vector product results are ready, the worker procedure reacquires the mutex lock and updates the not_done counter of work not yet completed. At the end of the matrix-multiply operation, the worker procedure that completes the last bit of work then signals the requesting thread. Each iteration computes the result of one entry in the result matrix. In some cases, the amount of computation could be insufficient to justify the overhead of synchronizing multiple worker procedures. In such cases, more work per synchronization should be given to each worker. For example, each worker could compute an entire row of the output matrix before synchronization.

Improving Time Efficiency With Two Threads
To save time, the preceding program could be run with a different number of threads and matrices of different sizes. The following examples show the results of testing two different thread/matrix combinations on a SPARCstation 10 with two 50MHz TMS390Z55 CPUs.
> matr_mult_1 Matrix size: 400 Number of worker threads: 1 Matrix multiplication time: 68 seconds. |
> matr_mult_2 Matrix size: 400 Number of worker threads: 2 Matrix multiplication time: 35 seconds. |
Use of Many Threads
The following example Pascal program, many_threads.p, is based on a similar C example in the Threads Primer (A Guide to Multithreaded Programming) by Bill Lewis and Daniel J. Berg. This example shows how to easily create many threads of execution in a Solaris environment. 
Debugging Multithreaded Pascal Programs
Using the dbx utility you can debug and execute programs written in Pascal. Both dbx and the SPARCworks Debugger support debugging multithreaded programs. Table 11-1 lists dbx options that support multithreaded programs.
Sample dbx Session
The following examples use the program many_threads.p.
> pc many_threads.p -o many_threads -mt -g
> stop at "many_threads.p":46
> stop at "many_threads.p":58
> run
Running: many_threads
(process id 12452)
t@1 (l@1) stopped in program at line 46 in file "many_threads.p"
46 writeln(i+1:1, ' threads have been created and are running!');
> lwps
l@1 breakpoint in program()
l@2 running in __sigwait()
l@3 running in _lwp_sema_wait()\x7f
l@4 running in ___lwp_cond_wait()
> cont
continuing all LWPs
Thread 4 is exiting...
Thread 5 is exiting...
...
Thread 102 is exiting...
Thread 103 is exiting...
execution completed, exit code is 0