




Using LoopReport |
23 |
 |
This chapter is organized as follows:
Basic Concepts
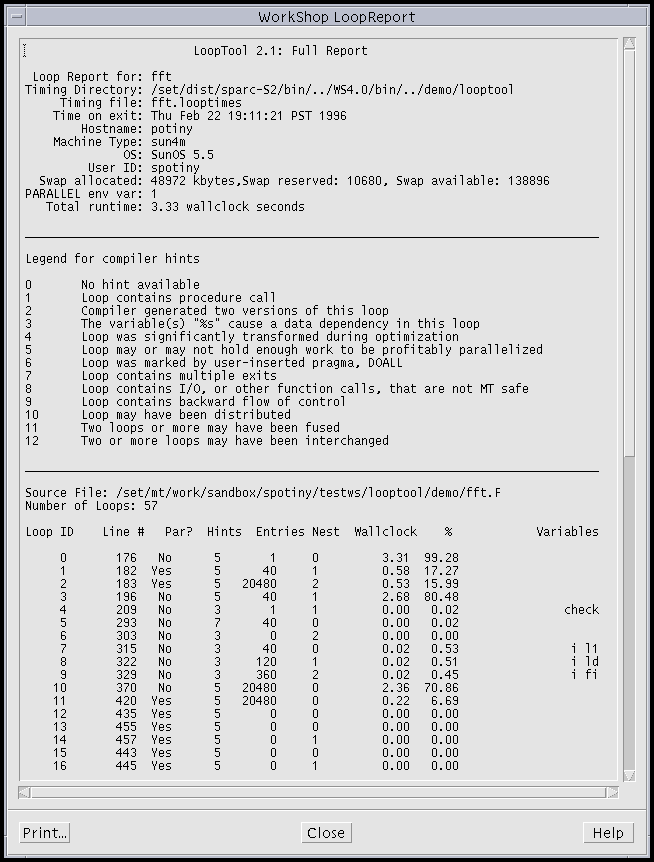
LoopReport is the command line version of LoopTool. LoopReport produces an ASCII file of loop times.
Note - The following examples use the Fortran MP (f77) compiler. The options shown (such as -xparallel and -Zlp) work also for MP C.
% setenv PARALLEL `/usr/sbin/psrinfo | wc -l` |
Note - If you have installed LoopReport in a non-default directory, substitute that path for the one shown here.
% setenv XUSERFILESEARCHPATH \
/opt/SUNWspro/lib/sunpro_defaults/looptool.res
% setenv LD_LIBRARY_PATH /usr/dt/lib:$LD_LIBRARY_PATH |
% setenv LD_LIBARY_PATH \ /opt/SUNWspro/Motif_Solaris24/dt/lib:$LD_LIBRARY_PATH |
% f77 -xO4 -xparallel -Zlp source_file |
After compiling with -Zlp, run the instrumented executable. This creates the loop timing file, program.looptimes. LoopReport processes two files: the instrumented executable and the loop timing file.
Note - All examples apply to Fortran77, Fortran90 and C programs.
Starting LoopReport
When it starts up, LoopReport expects to be given the name of your program. Type loopreport and the name of the program (an executable) you want examined.
% loopreport program |
% loopreport > a.out.loopreport |
You can also direct the output into a file, or pipe it into another command:
% loopreport program > program.loopreport % loopreport program | more |
Timing File
LoopReport also reads the timing file associated with your program. The timing file is created when you use the -zlp option, and contains information about loops. Typically, this file has a name of the format program.looptimes, and is found in the same directory as your program.
% loopreport program newtimes > program.loopreport |
% loopreport program -p /home/timingfiles > program.loopreport |
% setenv LVPATH /home/timingfiles % loopreport program > program.loopreport |
% loopreport program > program.loopreport % loopreport program | more |
% f77 -x04 -xparallel -Zlp source_file |
There are several other useful options for examining and parallelizing loops.
|
Option |
Effect |
|
-o program |
Renames the executable to program |
|
-xexplicitpar |
Parallelizes loops marked with DOALL pragma |
|
-xloopinfo |
Prints hints to stderr for redirection to files |
|
You type: |
Bumped Up: |
|
-xparallel |
-xparallel -xO3 |
|
-xparallel -Zlp |
-xparallel -xO3 -Zlp |
|
-xexplicitpar |
-xexplicitpar -xO3 |
|
-xexplicitpar -Zlp |
-xexplicitpar -xO3 -Zlp |
|
-Zlp |
-xdepend -xO3 -Zlp |
The -xexplicitpar and -xloopinfo have specific applications.
-xexplicitpar
The Fortran MP compiler switch -xexplicitpar is used with the pragma DOALL. If you insert DOALL before a loop in your source code, you are explicitly marking that loop for parallelization. The compiler will parallelize this loop when you compile with -xexplicitpar.
subroutine adj(a,b,c,x,n) real*8 a(n), b(n), c(-n:0), x integer n c$par DOALL do 19 i = 1, n*n do 29 k = i, n*n a(i) = a(i) + x*b(k)*c(i-k) 29 continue 19 continue return end |
% f77 -xO3 -parallel -xloopinfo -Zlp gamteb.F 2> gamteb.loopinfo
do 10 i=1,17 do 10 j=1,50 ...some code... 10 continue |
for (i=0; i<17; i++)
for (j=0; j<42; j++)
for (k=0; k<1000; k++)
do something;
for (i=1; i<10; i++) for (j=1; j<10; j++) do something; |
for (i=0; i<10; i++) {
a[i] = b * c; d[i] = a[i] + e; } |
Some of the hints are redundant; that is, two hints may appear to mean essentially the same thing.
Note - The hints are gathered by the compiler during the optimization pass. They should be understood in that context; they are not absolute facts about the code generated for a given loop. However, the hints are often very useful indications of how you can transform your code so that the compiler can perform more aggressive optimizations, including parallelizing loops.
Let Sun know which of the hints help you or what other sorts of hints you need from the compiler. You can send feedback by using the Comment form available from the About box in the LoopTool GUI. See WorkShop: Beyond the Basics for more information about the LoopTool GUI.
Finally, read the sections in the Fortran User's Guide and C User's Guide that address parallelization. There are useful explanations and tips inside these manuals.
The table lists the optimization hints applied to loops.
c$par DOALL |
do 99 i=1,n |
If the compiler hints seem particularly opaque, consider compiling with -O3
In particular, if you notice "phantom" loops--that is, loops that the compiler claims to exist, but which you know do not exist in your source code--this could well be a symptom of inlining.
LoopReport attempts to provide you with hints that make as much sense as possible. Given the nature of the problem of associating optimized code with source code, however, the hints may be misleading. If you are interested in this topic, refer to compiler books such as Compilers: Principles, Techniques and Tools by Aho, Sethi, and Ullman, for more information on what these optimizations do for your code.
Each loop is stipulated to use the wallclock time of each of its loop iterations. If an inner loop is parallelized, it is assigned the wallclock time of each iteration, although some of those iterations are running in parallel.
However, the outer loop is only assigned the runtime of its child, the parallel loop, which will be the runtime of the longest parallel instantiating of the inner loop.
This leads to the anomaly of the outer loop consuming "less" time than the inner loop. Keep in mind the funny nature of time when measuring events that occur in parallel, and this will help keep all wallclock times in perspective.