



Next: Dependency on |R| and
Up: Experimental Evaluation
Previous: Dependency on XR and XQ
We now want to look at the influence of a parameter that is imposed by
the data, namely the average length of the intervals of a
temporal relation. Obviously, the amount of overlapping intervals
grows if is increased. This can influence the performance
levels that result from the various strategies. In this section, we
want to investigate the relationship between and the
performance.
For that purpose, we used our base relations R and Q which both
have . We applied the procedure
change_lengths (see
appendix C) to derive relations
and with
average interval length respectively. Values for were
200, 400, 600, 800, 1000 and 1200. The corresponding profiles and are listed in
appendix D. With increasing the profiles become
smoother, showing less significant peeks than for low values of
.
In the experiments, we simulated the performances of the joins
, and for the values of that are listed above. In
order to restrict the combinatorical complexity, we concentrated on
one partitioning strategy per family, namely the uniform
lifespan , the primary
underflow and the primary
minimum-overlaps strategies.
All these strategies have been the best performing members of their
families in most cases so far. Tables 10.11
and 10.12 show the performance results (in sec.) for the
parallel and for the single-processor architecture, respectively. As
before, it is difficult to see the effects by simply looking at the
absolute numbers. Therefore we have visualised the results in
figures 10.24, 10.25 and 10.26 for
the parallel architecture and in figures 10.27,
10.28 and 10.29 for the single-processor
architecture.
In the parallel case, we can recognise significant differences depending
on the join:
- For the joins - where the profiles of
both participating relations are periodic - we find that the primary
underflow strategy performs best for low whereas the primary
minimum-overlaps strategy is the clear winner for high values of .Obviously, the longer the intervals become the more overlaps occur and
the more relevant the problem of overlaps becomes. This seems to favour
the primary minimum-overlaps strategy for high values of .
- For the joins - where the profile of
one relation is periodic whereas the other one's profile is
non-periodic - we find that the primary minimum-overlaps strategy
performs best or at least close to the best for all values of .The reason behind this is the same as in the previous case.
- For the joins - where the profiles of
both participating relations are non-periodic - we find that the
primary underflow strategy performs best for all . Its advantage
over the other strategies seems to increase for a growing . This
stands in contrast to the two other joins and is due to the fact that
the 's profiles (see figures D.7
to D.12 in appendix D) offer less and less
opportunities to set a breakpoint in a valley with an increasing
. The primary minimum-overlaps strategy, however, usually tries
to take advantage of such opportunities which it cannot in this
particular case. It is therefore that the primary underflow strategy,
which focuses on a good load balance , proves to
provide better performances.
We then took the average for the three strategies over the three joins
per value of . The times were normalised in the same way as
described in section 10.2 in order to guarantee a
fair comparison. Figure 10.30 shows the normalised
performances. We note that these averages suggest that the primary
underflow strategy performs best in most cases. This stands in contrast
to the more detailed analysis above. However, it is possible to
recognise a trend that the performances of primary underflow and
primary minimum-overlaps partitioning approach the one of uniform
lifespan partitioning. This is not surprising when we consider the
profiles of the relations that were used in the experiments (see
appendix D): with an increasing they loose their
respective periodic and non-periodic characteristics and approach a
profile of for uniform data which has a constant profile, i.e. 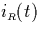 and would be constant.
and would be constant.
Now, we turn to the results that were obtained for the
single-processor architecture. These are shown in
table 10.12 and in figures 10.27
to 10.29. In contrast to the parallel case, we cannot
observe any advantages for a particular strategy for low or high
values of . The normalised averages in figure 10.31
show a slow convergence with an increasing .
In summary, it is fair to say that the average interval length is a significant parameter in the case of a parallel architecture
whereas it is almost neglectable on single-processor machines. For
parallel join processing, however, we conclude that low values of
favour the primary underflow strategy, whereas high cause
the periodicity or non-periodicity of the participating relations'
profiles to be a distinguishing factor. The presence of periodic
profiles suggests that primary minimum-overlaps partitioning is the
a good choice whereas the absence of such profiles indicates advantages
for the primary underflow strategy.
Figure:
Performances for the joins on the
parallel architecture.
|
Figure:
Performances for the joins on the
parallel architecture.
|
Figure:
Performances for the joins on the
parallel architecture.
|
Figure:
Performances for the joins on the
single-processor architecture.
|
Figure:
Performances for the joins on the
single-processor architecture.
|
Figure:
Performances for the joins on the
single-processor architecture.
|
Figure:
Comparison between the performances of the three strategies
on a parallel architecture with a varying .
|
Figure:
Comparison between the performances of the three strategies
on a single-processor architecture with a varying .
|
Next: Dependency on |R| and
Up: Experimental Evaluation
Previous: Dependency on XR and XQ
Thomas Zurek