



Next: Influence of the Condensation
Up: Experimental Evaluation
Previous: Dependency on |R| and
In experiment 1 of section 8.5, we already tried to find out
which parallel architecture, i.e. which type and which mixture of
SMP-nodes, would be most appropriate. Here, we repeat this experiment.
This time, however, the workload will not be uniform but
skewed . As in section 8.5, the /combinations 1/16, 2/8, 4/4, 8/2 and 16/1 will be investigated, i.e. there will be a total of processors in all cases.
As before, we will run the three joins , 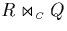 and
on these architectures using the uniform lifespan (with
m=384), the primary underflow (with , ) and the primary minimum-overlaps (with , ) strategies.
and
on these architectures using the uniform lifespan (with
m=384), the primary underflow (with , ) and the primary minimum-overlaps (with , ) strategies.
Table 10.15 shows the results of these experiments. The
performances are visualised in figures 10.36,
10.37 and 10.38. Overall, the shapes of
the cost graphs are similar to the one of figure 8.15
(page ![[*]](cross_ref_motif.gif) ). However, there are three effects which
are slightly out of line:
). However, there are three effects which
are slightly out of line:
- For the joins and the combination
/ seems to make a difference, at least for underflow and
minimum-overlaps partitioning. 4/4, 8/2 and 16/1 are the favourable
combinations, causing only around 40% of the costs in most cases and
in comparison to the 1/16 architecture. However, this is higher
than in experiment 1 of section 8.5 where the 4/4, 8/2
and 16/1 architectures had only around 26% of the costs of the
1/16 architecture. This proves again that the somewhat unrealistic
assumption of uniformity presented a distorted picture of the
figures that can be expected for real applications.
- For the join , the performance advantage of the 4/4,
8/2 and 16/1 combinations is between 10% and 20% for all strategies in
comparison to the 1/16 architecture. This is rather low when compared
to the 60% gains for the other joins.
- For the join , the performance results for
uniform partitioning are almost the same between the architectures.
On the other hand, the results change a lot for primary underflow
and primary minimum-overlaps partitioning.
The effects that we have observed here can be explained by looking into
the components that contribute to the costs. These are shown in
tables 10.16, 10.17 and 10.18
respectively. As an example, the numbers for the primary underflow
strategy were visualised in figures 10.39,
10.40 and 10.41. For the joins and , we find that the memory access costs dominate the
processing of the subjoins for the 1/16 and 2/8 architectures whereas
the CPU costs dominate in the case of the 4/4, 8/2 and 16/1
architectures. In the case of the join it is the CPU costs
that dominate in most situations. Therefore, the mixture between
closely and loosely coupled processors is not as significant as for
the other joins. This can also be seen in the case of uniform lifespan
partitioning for the join . In contrast to primary
underflow and primary minimum-overlaps partitioning we find here that
the CPU costs dominate on each one of the architectures. Therefore
there is hardly any performance difference in that case.
Finally, we tried to compute performance marks for the five
architectures in order to find the best one out. For that purpose, we
normalised the performance results of table 10.15 in the
following way: first, the costs with uniform lifespan partitioning (for
a certain join and on a certain architecture) were assumed to represent
a value of 100; then, the other cost values were transformed to express
the costs in comparison to the 100 that represented the corresponding
uniform lifespan partitioning value; finally the average per architecture
was taken over all cost results. Table 10.19 shows
the new numbers and figure 10.43 visualises the averages.
The 4/4, 8/2 and 16/1 architectures are the clear winners in that
comparison - a conclusion that has already been drawn from the
results of section 8.5.
Figure:
Performance results for the on varying parallel
architectures.
|
Figure:
Performance results for the on varying parallel
architectures.
|
Figure:
Performance results for the on varying parallel
architectures.
|
Figure:
Comparison of the five parallel architectures.
|
Next: Influence of the Condensation
Up: Experimental Evaluation
Previous: Dependency on |R| and
Thomas Zurek