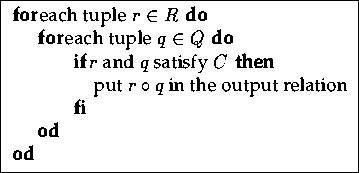This is the simplest join technique. It is based on equation (3.1). One of the relations being joined, say R, is designated as the outer relation , and the other one, Q, as the inner relation . From the correctness point of view, it does not matter which of the two participating relations is the outer and which is the inner relation.
For each tuple r of the outer relation, all tuples q of the
inner relation are read and compared with the tuple from the outer
relation. Whenever the join condition C is satisfied, the two tuples
are concatenated to form a tuple ![]() which is placed in
an output relation.
which is placed in
an output relation.
In other words: each tuple of the cartesian product ![]() is tested on the join condition C. If it
satisfies C then it is included into the join result.
Figure 3.6 summarises the algorithm.
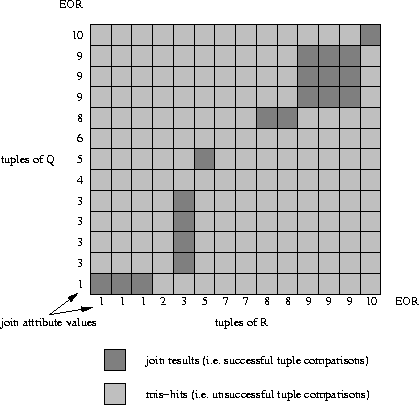
Figure 3.7 gives a visual example of how the algorithm
finds the join result: tuples of R are scattered along the
horizontal axis; the respective value of the join attribute is put
below each of the resulting columns. Similarly, the tuples of Q are
put along the vertical axis. The resulting grid represents every
possible comparison between tuples of R and Q and as such the
search space of the join, i.e. the cartesian product
is tested on the join condition C. If it
satisfies C then it is included into the join result.
Figure 3.6 summarises the algorithm.
Figure 3.7 gives a visual example of how the algorithm
finds the join result: tuples of R are scattered along the
horizontal axis; the respective value of the join attribute is put
below each of the resulting columns. Similarly, the tuples of Q are
put along the vertical axis. The resulting grid represents every
possible comparison between tuples of R and Q and as such the
search space of the join, i.e. the cartesian product ![]() .Comparisons that satisfy the join condition, i.e. tuple combinations
that contribute to the join result, are shown in dark grey whereas
unsuccessful comparisons are put in light grey. The figure shows that
the brute force nested-loops join performs an exhaustive search over
the cartesian product.
.Comparisons that satisfy the join condition, i.e. tuple combinations
that contribute to the join result, are shown in dark grey whereas
unsuccessful comparisons are put in light grey. The figure shows that
the brute force nested-loops join performs an exhaustive search over
the cartesian product.
The brute force nested-loops join is frequently referred to simply as a nested-loop join. C.J. Date, however, pointed out that this is misleading as all the other join techniques also use nested loops in one or the other way [Date, 1995]. For simplicity and because of the fact, that it has become a commonly accepted expression, we will stick to calling it `nested-loop join' in the remainder of the thesis.
In practice, the nested-loop join is implemented as a nested-block join [El-Masri and Navathe, 1994]: instead of retrieving one tuple each time, an entire block of tuples is read from disk and cached in main memory. This is more efficient because, this way, several random accesses are replaced by sequential tuple accesses which are faster. A further performance improving measure is to use the relation with the lower cardinality as the outer relation in order to reduce the I/O costs which are given by the formula
| |
(6) |
Furthermore, we can switch the direction in which the inner relation is read each time. This has the advantage that the last block read by the previous inner loop is the first block of the oncoming inner loop. It still is in a memory buffer and therefore does not need to be read from disk. This method is called rocking and was proposed by [Kim, 1980]. Naturally, every method that accelerates disk access to tuples, such as using an index, helps to improve the performance of the algorithm.
The problem of the nested-loop join lies in the exhaustive matching. Whenever the join condition C causes only a small fraction of the cartesian product to be part of the join result the nested-loop technique performs a large quantity of unsuccessful comparisons (see if-statement in figure 3.6). Such a situation is characterised by a low join selectivity [Piatetsky-Shapiro and Connell, 1984] which is defined as
 |
(7) |