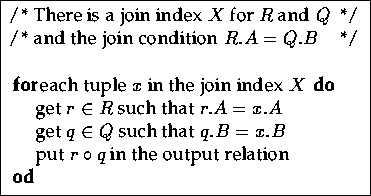The class of data-structure-assisted joins makes use of special data structures which can be regarded as some kind of index. Many such data structures have been proposed, such as join indexes [Valduriez, 1987], Bc-trees [Goyal et al., 1988], T-trees [Lehman and Carey, 1986], kd-trees [Kitsuregawa et al., 1989] and domain vectors [Perrizo et al., 1991] or bitmap indices [O'Neil and Graefe, 1995]. We will shortly describe the first one. A more detailed summary of data-structure-assisted join can be found in section 3 of [Mishra and Eich, 1992].
A join index is a binary relation with two foreign key
attributes![[*]](foot_motif.gif) . A tuple in the join
index describes a pair of tuples that participate in the join result by
referring to the tuples in the input relation through the respective
foreign key attribute value. Alternatively, foreign key values can be
replaced through physical addresses or any other logical value - a
surrogate - that uniquely identifies a tuple
in an input relation. Figure 3.15 shows the
(equi-)join algorithm based on a join index. Similarly to the preceding
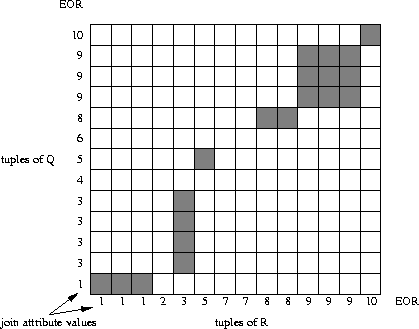
sections, figure 3.16 shows the search strategy
employed by the algorithm. There are no mis-hits because the join is
virtually precomputed.
. A tuple in the join
index describes a pair of tuples that participate in the join result by
referring to the tuples in the input relation through the respective
foreign key attribute value. Alternatively, foreign key values can be
replaced through physical addresses or any other logical value - a
surrogate - that uniquely identifies a tuple
in an input relation. Figure 3.15 shows the
(equi-)join algorithm based on a join index. Similarly to the preceding
sections, figure 3.16 shows the search strategy
employed by the algorithm. There are no mis-hits because the join is
virtually precomputed.
Once created, a join index has to be maintained which might cause a considerable overhead: each time the input relations are updated the referential integrity has to be checked in order to keep the join index consistent. With a growing join selectivity the size of the join index approaches that of the cartesian product. This expense must be justified by frequent joins of the relations involved.