



Next: Basic Concepts and Notations
Up: Temporal Databases
Previous: Temporal Databases
Temporal databases store temporal
data , i.e. data that is time-dependent
(time-varying). Typical temporal database scenarios and applications
are the following:
- Economical data is frequently time-dependent: share
prices, exchange rates, interest rates, company profits etc. vary
over time. This means that we need to store not only the respective value
but also an associated date or a time period for which the value is
valid. Typical queries, for example, are
- Give me last month's history of the Dollar - Pound Sterling
exchange rate.
- Give me the share prices of the NYSE on October 17, 1996.
More sophisticated analysis might want to correlate interest rates
and exchange rate or share prices trends. This means that an interest
rate value has to be related to an exchange rate value using the
date or period for which the values are valid: they have to be valid
during the same period of time in this example.
- Many companies offer products whose prices vary over time.
Daytime telephone calls, for example, are usually more expensive than
evening or weekend calls. Travel agents, airlines or ferry companies
distinguish between high and low seasons. Sports centres offer squash
or tennis courts at cheaper rate during the day. Hence, prices are
time-dependent in these examples. They are typically summarised in
tables with prices associated with a time period. In terms of a
relational temporal data model this is a temporal relation.
- Our all-day-life is very often influenced by timetables for
buses, trains, flights, university lectures, laboratory access and
even cinema, theatre or TV programmes. As one consequence, many
people plan their daily activities by using diaries which itself is a
kind of timetable. And again: timetables or diaries can be regarded as
temporal relations in terms of a relational temporal data model.
- Medical diagnosis often draws conclusions from a patient's
history, i.e. from the evolution of his/her illness. The latter is
described by a series of values, such as the body temperature,
cholesterol concentration in the blood, blood pressure etc. As in the
first example, each of these values is only valid during a certain
period of time (e.g. a certain day). Typically a doctor would
retrieve a patient's values' history, analyse trends and base his
diagnosis on his observations.
Similar examples can be found in many areas that rely on the
observation of evolutionary processes, such as environmental studies,
economics and many natural sciences.
Temporal database management systems (TDBMS) support the maintenance and
manipulation of temporal data in many possible ways. Temporal support
can affect many but not necessarily all of the following issues:
- 1.
- It can provide an entire temporal data model which consists of a temporal data definition language
(DDL) and a temporal data manipulation language
(DML) . This means that temporal objects can be defined via
the DDL and can be created, updated, deleted and retrieved via the
DML.
- 2.
- User-defined time is already an integral part of the relational
data model (time is considered as a domain such as integers or
strings). Thus there might be a temporal query
language that simply offers a set of
temporal operators and predicates to enhance the search facilities.
- 3.
- Finally, there are various performance related issues such as
temporal storage structures or the implementation of temporal
operators.
We note that 1. and 2. are alternatives that actually depend on the degree of temporal
support that one wants to achieve: 1. implies a
temporal query language whereas 2. only
enhances the very basic temporal facilities given by conventional data
models. Any of these two cases will require to be supported by a
proper implementation as pointed out in 3.
Points 1. and 2. above
expose a very variable degree of possible temporal support that can be
provided by a database management system (DBMS) .
Furthermore, we note that a temporal database does not require a TDBMS
at all. Temporal databases have existed for many years using
conventional![[*]](foot_motif.gif) DBMS.
DBMS.
These facts are in the centre of a controversy between researchers who
support the wide integration of temporal specific features into
conventional DBMS and their critics. Davies et al., for example,
argue that it is not necessary to provide specific support for
temporal data processing but that there are certain general,
non-temporal-specific features that have to be incorporated into
relational query languages, such as recursion. The latter would not
only support temporal features, such as coalescing (see below), but
would prove to be useful for many non-temporal situations too
[Davies et al., 1995].
One issue of concern is related to the following fact that traditional
query languages do not support the many constructs that natural
language provides when referring to time or temporal relationships.
This not only decreases the user-friendliness of the query language
but imposes considerable problems on the query optimiser. Let us look
at the following example: Take the sentence ``Jack studied at
university at the same time as Mark.'' Using the intervals
[js,je] and [ms,me] for representing the
respective study start and end dates for Jack and Mark, we can
describe the `same time as'
relationship by the expression
| 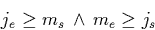 |
(1) |
which pays attention to the fact that `same time as' does not
necessarily mean that Jack and Mark started and finished at the same
time but that Jack and Mark were both at university during a certain
period of time. Furthermore, it relies on the additional constraints
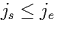 and
and 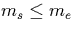 .
Alternatively, one could say
.
Alternatively, one could say
It should be obvious that neither (2.1) nor
(2.2) are straightforward expressions. Things become
worse when we consider the fact that most SQL queries are generated
automatically by query tools nowadays. Such tools create queries that
express the desired query somehow but not necessarily efficiently as
this task is left to a query optimiser. Query
optimisation , however, is in general a hard
problem [Ryan and Smith, 1995]. Although expressions such as
(2.2) can theoretically be reduced to
(2.1) or to another, less complex expression, it is
difficult for an optimiser to recognise and optimise this in practice
within a reasonable time frame. In general, if a query tool produces
an awful query then there is not much that the optimiser can do about
it.
For temporal queries, a possible solution to this problem is to provide
temporal operators and predicates that are close to the natural way of
expressing the respective relationship. In the case of
(2.1) and (2.2) this could be a
predicate called `intersects' which would enable us
to say
| ![\begin{displaymath}[j_s,j_e]
\text{\it \quad intersects \quad} [m_s,m_e]\end{displaymath}](img10.gif) |
(2) |
Expressions, such as this one, not only make the queries less complex
and therefore user-friendly but also opens the opportunity to optimise
queries semantically:
Conventional
DBMSs are tuned to perform well on many standard operations. As seen
above, temporal queries are more likely to involve complex constructs
like (2.1) or (2.2), e.g. as a join
condition. Optimisation techniques can cope with these to a certain
extent but they are likely to result in a poor performance. If
temporal specific constructs are provided by the (declarative) query
language then more efficient, temporal specific query evaluation
strategies can be applied: imagine a query containing
(2.3) as a sub-expression. If an optimiser does not
know that js, je and ms, me are the respective start- and
endpoints of some timestamp intervals then it does
not know about many implicit and and possibly helpful constraints
either. Examples for such constraints are:
- A startpoint of a timestamp cannot lie
beyond the endpoint, i.e.
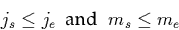
- Transaction time is restricted
to the past and the present. Therefore transaction time
timestamps are bound by the current time which is
usually referred to as `now' . If [js,je]
and [ms,me] are such timestamps then we know that
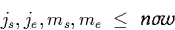
Such implicit conditions can be possibly exploited to increase the
performance of query evaluation. To that end, the optimiser must know
about the semantics - in this case: temporal
semantics - of the data.
Among all the arguments for and against temporal-specific support,
performance and efficiency of temporal query processing are the least
controversial. Many authors have recognised that conventional
techniques, such as index structures or join algorithms, are tuned for
performing well in standard situations, i.e. atomic data types,
equality conditions, etc. These are not necessarily suited to temporal
query processing where problems like non-atomic data, temporal
predicates, granularity, schema versioning, multiple calendars etc. occur.
In this thesis, we will deal with joins that are based on
temporal join conditions, i.e. expressions similar to
(2.1) or (2.3). We will show that
providing specific techniques for temporal join evaluation is much
more efficient than using conventional mechanisms.
In the 1980s, observations, like the ones described above, triggered a
large number of research efforts on the development of temporal
database systems. Most researchers concentrated on extending the
relational model with temporal features. Some selected examples are
HQuel [Tansel, 1986], TQuel [Snodgrass, 1987], the temporal features
of Postgres [Stonebraker, 1987], [Stonebraker et al., 1990], DM/T
[Jensen et al., 1991], TempSQL [Gadia, 1992] or IXSQL
[Lorentzos and Mitsopoulos, 1997]. An impression and overview of temporal database
research can be obtained from the temporal database bibliographies
that have been published regularly in the SIGMOD Record. The latest
two were presented in 1993 [Kline, 1993] and 1996 [Tsotras and Kumar, 1996].
Many research efforts were brought together when a group of
researchers discussed a temporal query language,
called TSQL2 [Snodgrass et al., 1994],
[Snodgrass, 1995], which was based on the SQL92 standard
[ISO92, 1992]. The TSQL2 design process tried to integrate many of the
features that had been proposed previously. Temporal database
researchers met at two workshops, [Pissinou et al., 1994] and [Clifford and Tuzhilin, 1995],
and published a book on temporal databases [Tansel et al., 1993]. Since
then, temporal databases have become a major topic of interest in
almost every database conference.
Currently, the ANSI and ISO committees that are creating the new
SQL3 standard are considering a temporal extension of SQL3
which is referred to as SQL/Temporal
[Darwen, 1997], [Snodgrass, 1996].
Next: Basic Concepts and Notations
Up: Temporal Databases
Previous: Temporal Databases
Thomas Zurek