In [3] the author explores the problem of implementing distributed recursive datatypes. The programming model that he uses is Single Program, Multiple Data. The SPMD model simplifies the problem of programming multiple processors by distributing the main data structures and having each processor follow through the same basic program, but operating only on its own local data. This immediately introduces the idea of a processor owning data . We consider a simple integer tree data type, implemented in a sequential language such as C++ (fig. 1.2).
In a one processor environment, a tree would consist of a number of such objects dynamically created in the single address space, linked together using the pointers. If we were to implement this in the most naive way in a distributed system, we would firstly need to introduce the idea of a global pointer, that stores the processor name along with the address of the data. The pointers left and right would then become global pointers. We could then distribute these objects amongst the processors. If we then wanted to map a function f over the tree (doubling the integer value, say) we would use code as in fig. 1.3.
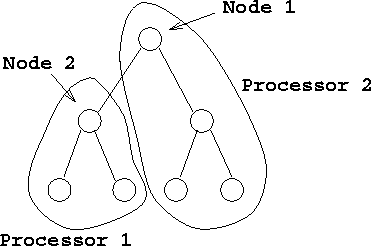
This introduces a problem. If the tree objects are stored on different processors then the pointers that link them together will also be stored on different processors. Then in order to traverse through the structure each processor will have to communicate with other processors to find what the sub parts of the structure are. In fig. 1.4, suppose that processor 1 wants to traverse from node 1 to node 2, which it owns. It must first communicate with processor 2, which owns node 1, in order to find which node is the correct one to move to. Ideally, we would want processor 1 to know the whole structure of the tree, realise that node 2 was the one it wanted to traverse to, and move there directly without any communication.
This introduces the notion of node naming . If we can allocate to each possible node in the structure a unique name, and a scheme for mapping nodes to processors then we will not need the communication. In principle, a node naming system works as follows. If x is a node in the structure with sub node s, then given the name n of x, we need to be able to generate the name of s. As a concrete example, for a binary tree it is simple to name each node using an integer. The root node would be named 1, and if n is the name of a node, then its left sub-node would be named 2n, and its right sub-node would be 2n+1. In [3] there is a simple default strategy for trees of degree k, or alternatively the user can supply their own.