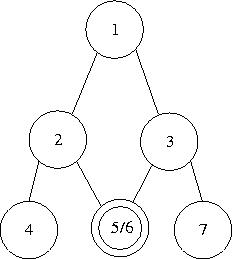
If we are dealing with a structure where there is some sharing of nodes, a situation that is caused by a node having more than one parent. There will then be more than one possible name for the node. In fig. 1.5, if we assume that we are using the naming scheme outlined above, the ringed node can be assigned two different names, depending on whether it was created from node 2, or node 3.
The method used in [3] deals with this firstly by naming the nodes in the aliased structure according to the names for an unaliased structure. This generates multiple names for the nodes (aliases ) which have to be created and manipulated together. So, for each node we need to maintain a unique name, plus a list of its aliases. If we then traverse through a node using an alias, we need to map that alias name to the unique name (normalisation ). If a parent node of an aliased node is then deleted, this may require the deletion of the unique name, in which case a new one will have to be chosen from the list of aliases, and any sub-nodes will then have to be re-named.
If we can set out in advance which nodes are going to be shared in the structure, then we can design a node naming strategy that will assign to each node a unique name, that can be computed regardless of the node from which it was reached. In the above situation where we have the redundancy from the commutativity of some of the directions, we know in advance which nodes are going to be shared, and can exploit this to produce a unique naming scheme.