



Next: The Interval Partitioning Problem
Up: Temporal Join Processing
Previous: A Short Summary
The discussions of temporal join techniques in
sections 4.3 and 4.4 have
shown that many performance related issues are not specific to temporal
joins but similar to the case of the equi-join which is well
investigated. Hence, many well-known optimisation techniques can be
applied when processing temporal joins.
However, the necessary replication of tuples in the case of range
partitioned joins is a problem which is specific to temporal joins.
As outlined in section 4.4.1, it produces
overheads of various types. Therefore, controlling the extent of
replication has to be a major task of the optimisation process for
these joins.
There are two problems that have to be solved:
- 1.
- The choice of the ranges, i.e. the partition points on the time
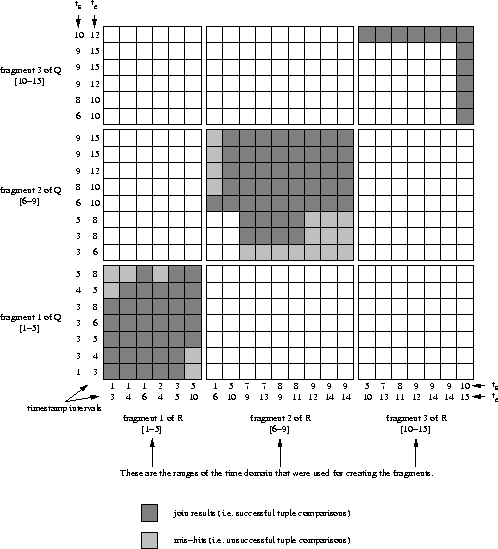
line, is a very delicate one. Consider, for example,
figure 4.17 which shows the scenario for our
join example when an alternative set of partitioning ranges is used:
more tuples have to be replicated, there are more mis-hits and the load
balance is slightly worse in comparison to the situation in
figure 4.11.
The main part of this thesis will look at this problem.
In chapter 5 we analyse the problem of finding partitioning
ranges that minimise the total number of replicated tuples while
preserving a certain maximum number of intervals per fragment.
Afterwards, in chapters 6-10, the problem is
tackled from a practical point of view: we develop and describe
an optimisation process for choosing a `good' partition for processing
a temporal join and show how this process can be efficiently implemented.
- 2.
- Query optimisers usually estimate the sizes of join
results . This information is used for
taking optimisation decisions and sometimes also to provide the user
with an estimate of the result size. This might help him/her to check
if his/her query delivers the desired result. If the optimiser's
estimate predicts a result size of 1 million rows, for example, while
the user expects only a handful then there is a good reason for the
user to assume that the query might have to be rewritten.
The
estimation of final and intermediate join results is already a
challenging task because of the nonequi-character of temporal join
conditions. It becomes even more difficult when tuples are replicated:
the sizes of the join fragments and the partial join results cannot be
computed by incorporating `static' facts - i.e. facts that are known
in advance from metadata information such as relation
size, number of different attribute values, distribution of these
values (e.g. in form of histograms) etc. - but also on query
evaluation parameters such as the replication of tuples imposed by the
partition ranges.
In chapter 11 we will show a method to
estimate temporal join selectivities. It is based on the same concepts
as the optimisation of the partitioning process that was motivated in
1.
Figure:
Search strategy for the improved (range) partitioned temporal
join with different partitioning ranges (compare with
figure 4.11).
 |
Next: The Interval Partitioning Problem
Up: Temporal Join Processing
Previous: A Short Summary
Thomas Zurek