



Next: Problem Definition
Up: The Interval Partitioning Problem
Previous: Introduction
Before formally investigating the complexity of the interval
partitioning problem, we introduce the notation that is used
in the remainder of the chapter.
- In this chapter, we adopt a general view of the interval partitioning
problem. Therefore we partition collections of intervals rather
than temporal relations. Later, in the context of temporal join
processing, we regard a temporal relation as a collection of intervals
by neglecting all attribute values other than the interval data.
To simplify the overall notation, we will use letters R
and Q or expressions like 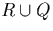 to refer to
collections of intervals, having in mind that these originate in
temporal relations R, Q or . Although being formally
incorrect we think that this improves the readability and avoids
confusing the reader. Similarly, we will use r and
q to refer to tuples and intervals depending on the
actual context.
to refer to
collections of intervals, having in mind that these originate in
temporal relations R, Q or . Although being formally
incorrect we think that this improves the readability and avoids
confusing the reader. Similarly, we will use r and
q to refer to tuples and intervals depending on the
actual context.
Formally, a collection of intervals is denoted by
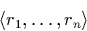
The difference between a set and a collection is that an element can
appear multiply in a collection but only once in a set. The
cardinality is defined accordingly. In summary, this means that if
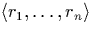 is the collection of intervals resulting from
a temporal relation R then
is the collection of intervals resulting from
a temporal relation R then
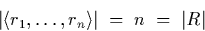
- Intervals are defined over a certain domain. For our purposes,
we can assume the set of integers to be the domain with the symbolic
infimum and supremum values
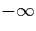 and
and 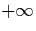 . We assume that
there is a total ordering defined on the domain. As outlined in
chapter 2, the set of integers is a reasonable
representation of time for our purposes. If t is a
timepoint then we refer to its predecessor by t-1
and to its successor by t+1.
. We assume that
there is a total ordering defined on the domain. As outlined in
chapter 2, the set of integers is a reasonable
representation of time for our purposes. If t is a
timepoint then we refer to its predecessor by t-1
and to its successor by t+1.
- Intervals have the notations that have
been introduced in section 2.2; the two that are
relevant here are [ts,te] and (ts,te] in which ts and te
are timepoints/instants. In that sense, the intervals comprise all
instances between and including the start- and endpoints in the case
of [ts,te] and all instances between the start- and endpoints,
excluding the start- but including the endpoint in case of
(ts,te]:
-
![$[t_s,t_e] = \{x: t_s \leq x \leq t_e\}$](img183.gif)
-
![$(t_s,t_e] = \{x: t_s < x \leq t_e\}$](img184.gif)
Please see section 2.2 for a more detailed discussion
of this notation.
We use the first type in the collection(s) of intervals that are
to be partitioned and the second type for the partitioning ranges
(see below).
- The range T(R) of a collection R
of intervals is the part of the domain covered by the intervals in
R; it is formally defined as
We will refer to the minimum of T(R) as 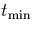 and to the maximum
as
and to the maximum
as 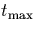 . The collection to which
and refer will always be obvious from the context.
. The collection to which
and refer will always be obvious from the context.
- The span L(R)
of a collection R of intervals is defined by
![\begin{displaymath}
L(R) = [t_{\min}, t_{\max}] \end{displaymath}](img185.gif)
The span may contain parts of the domain that are not covered by
any interval and are therefore not included in the range T(R).
- The sets of interval startpoints, S(R) , and
endpoints, E(R) , are defined by
- A partition P is an
ordered
![[*]](foot_motif.gif) set
set
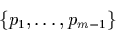
of breakpoints that divide the span and
range into m segments or
partition ranges (pk-1,pk] for
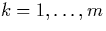 with p0 and pm being defined appropriately:
suitable values, for example, are
with p0 and pm being defined appropriately:
suitable values, for example, are
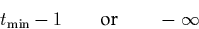
for p0 and
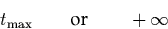
for pm . We do not consider p0 and pm to be part
of a partition P for two reasons: (a) they can be the same for all
possible partitions and (b) they do not actually influence the
performance characteristics of P as we will see later.
The difficult choice is to determine the p1, ..., pm-1
and this is our main concern.
- In order to calculate the impacts of a partition, we use the
following functions which are assumed to be defined on the entire
set of integers although non-zero values only occur for
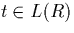 :
:
Figure:
Search strategy for the improved (range) partitioned temporal
join with different partitioning ranges (compare with
figure 4.11).
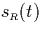 |
= |
number of intervals in R that start at point t |
= |
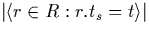 |
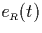 |
= |
number of intervals in R that end at point t |
= |
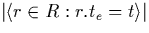 |
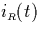 |
= |
number of intervals in R that include point t |
= |
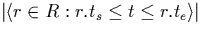 |
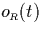 |
= |
number of intervals in R that overlap point t |
= |
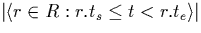 |
| |
|
(i.e. they include t but do not end at t) |
|
|
The functions 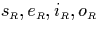 will prove to be quite useful
for demonstrating a variety of properties. Actually, each of them
can be expressed by using two of the others. Their
relationships can be derived from the three basic properties that
are obvious from the definition of
will prove to be quite useful
for demonstrating a variety of properties. Actually, each of them
can be expressed by using two of the others. Their
relationships can be derived from the three basic properties that
are obvious from the definition of 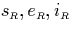 and
and 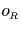 :
:
and
| 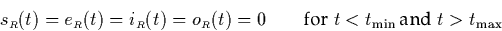 |
(11) |
Equation (5.1) reflects the fact that the intervals that
overlap t are those that include t apart from those that end at
t. Equation (5.2) considers that intervals that include
t must either start at t - these are counted by - or
have started at t-1 or before without ending at t-1 - these are
counted by 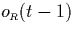 . Finally, (5.3) is rather trivial
as it indicates that nothing goes on outside the range T(R).
. Finally, (5.3) is rather trivial
as it indicates that nothing goes on outside the range T(R).
If at least two of the functions are known then
we can compute the missing ones by using equations (5.1),
(5.2) and (5.3). Figure 5.1
shows the equations that can be derived. The case of having the
values and - this corresponds to
figure 5.1(a) - is a little bit tricky because the
equations are recursive: Replacing in (5.1) by
using (5.2) delivers
| 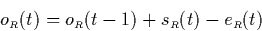 |
(12) |
which works out to be
| 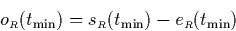 |
(13) |
as we can derive 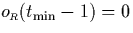 from (5.3).
Using (5.5) as a starting point, subsequent values can
be calculated by applying (5.2) or (5.4)
respectively.
from (5.3).
Using (5.5) as a starting point, subsequent values can
be calculated by applying (5.2) or (5.4)
respectively.
The remaining equations shown in figure 5.1 result
from algebraic transformations and combinations of equations
(5.1) and (5.2).
Figure:
Relationships between 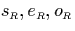 and
and 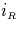 .
.
![\begin{figure}
\begin{footnotesize}
\mbox{
\subfigure[~]{
\fbox {
\begin{mini...
...criptstyle R}(t)\end{eqnarray*}\end{minipage}}
}
}\end{footnotesize}\end{figure}](img210.gif) |
Next: Problem Definition
Up: The Interval Partitioning Problem
Previous: Introduction
Thomas Zurek