



Next: Improved Temporal Hash Join
Up: Explicit-Partitioning Join Algorithms
Previous: Overview
The symmetric partitioning approach, as outlined by equation
(3.6)
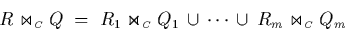
can be adapted for processing temporal intersection joins. We assume
that the partial joins are to be kept independent thus allowing
concurrent processing. Then, the fragments cannot be created by
hashing the tuples over their interval timestamps :
assume that there was a hash function
h such that intersecting intervals are assigned to the
same fragment number. Assume also that there are at least two
different fragments per relation to be created. Let [xs,xe] and
[ys,ye] be two non-intersecting intervals, i.e. 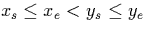 , which are assigned to two different fragments i and
j by h, i.e.
, which are assigned to two different fragments i and
j by h, i.e.
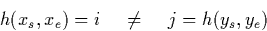
Now consider the interval [xe,ys] which should fall into fragment
i because it intersects with [xs,xe] and also into fragment j
because it intersects with [ys,ye]. Thus h would have to assign
two different values, i and j, for [xe,ys] which contradicts
its notion of being a function.
Nevertheless, we can employ range partitioning
as a variation of hash partitioning. Here, tuples are partitioned over
their interval timestamp in the following way: the time line is
divided into m disjoint ranges which are numbered according to their
order on the time line. If a relation, say R, is partitioned then a
tuple 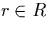 is put into Rk if its timestamp
interval intersects with the k-th range. We note that a tuple can be
put into several fragments because its timestamp interval might
intersect with more than one time range.
is put into Rk if its timestamp
interval intersects with the k-th range. We note that a tuple can be
put into several fragments because its timestamp interval might
intersect with more than one time range.
In general, it is impossible to create disjoint fragments for interval
data if a temporal relation R has a long `chain' of intervals, i.e. [r1.ts,r1.te], ..., [rn.ts,rn.te] such that subsequent
intervals intersect, i.e.
![\begin{displaymath}[r_i.t_s,r_i.t_e]
\cap [r_{i+1}.t_s,r_{i+1}.t_e] \not= \emptyset\end{displaymath}](img147.gif)
Then it is impossible to put these intervals into different fragments
without assigning at least one of them to two different fragments: if
[r1.ts,r1.te] goes to fragment k then [r2.ts,r2.te] has
to go to fragment k, too, because it intersects with
[r1.ts,r1.te]. The same applies to [r3.ts,r3.te] because
it intersects with [r2.ts,r2.te], and so forth. However, our
intention is to partition the data in order to reduce the processing
effort and to improve resource utilisation (disk I/O, main memory).
It is therefore out of the question to put all the n intervals into
the same fragment if n is very large; in general, it is likely that
n is close or equal to |R|. In this case, the `chain' has to be
broken into two or more parts which forces one or more intervals to be
put into more than one fragment.
If tuple replication is tolerated as a necessary evil, one can apply
the symmetric partitioning technique as described in
section 3.5.2. Figure 4.8 shows the
search strategy of the technique when the partial joins are processed
as nested-loops. It also shows two major problems related to
the processing overhead and the duplicates
overhead :
- Tuple replication causes repetitions of possible tuple comparisons.
The net effect of this is the same as if the search space is
increased. The fragments themselves are larger. In
figure 4.8, 132 tuple comparisons are performed. When
comparing this number with the 182 of the nested-loop join
(figure 4.2) we recognise that the partitioning
effort is not as successful as one might have hoped.
- Some of the successful tuple comparisons are duplicated too.
These cause duplicate tuples in the join result. In
figure 4.8, these comparisons are marked in black. They
occur, say, in the k-th partial join
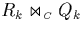 , and are
actually unnecessary because they are also performed by another partial
join
, and are
actually unnecessary because they are also performed by another partial
join 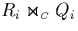 with i<k. In many situations, duplicates
have to be removed from the join result by expensive operations. This
increases the overall overhead furthermore.
with i<k. In many situations, duplicates
have to be removed from the join result by expensive operations. This
increases the overall overhead furthermore.
In the following section, we will tackle these problems by refining the
simple approach presented here.
Figure:
Search strategy for the simple partitioned temporal join (partial
joins as nested-loops).
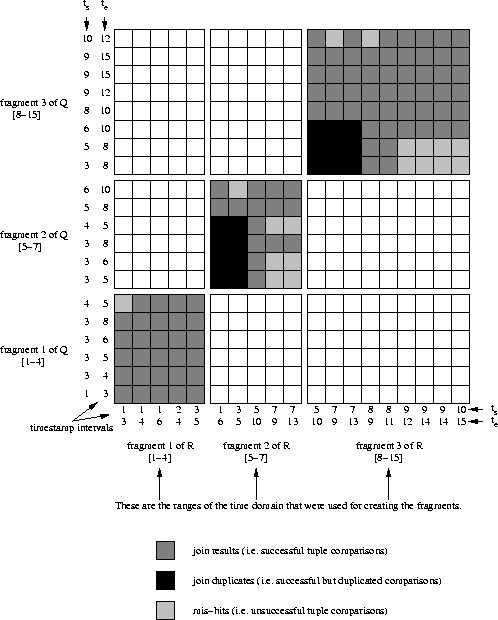 |
Next: Improved Temporal Hash Join
Up: Explicit-Partitioning Join Algorithms
Previous: Overview
Thomas Zurek